✅ Link to the plugin page: https://zeroqode.com/plugin/deepseek-ai-models-plugin-for-bubble-1738940557670x217102696505632860
Demo to preview the plugin:
Introduction
DeepSeek AI is an advanced plugin that leverages AI technology to optimize search and data analysis. It helps quickly find relevant information, process large datasets, provide personalized recommendations, and automate routine tasks—perfect for professionals seeking smarter solutions.
Our plugin allows you to create a full-fledged chat with the Deepseek artificial intelligence, as well as complete sentences
Prerequisites
You must have an API Key for DeepSeek. You can obtain the API key on this page - https://platform.deepseek.com/sign_in
How to setup
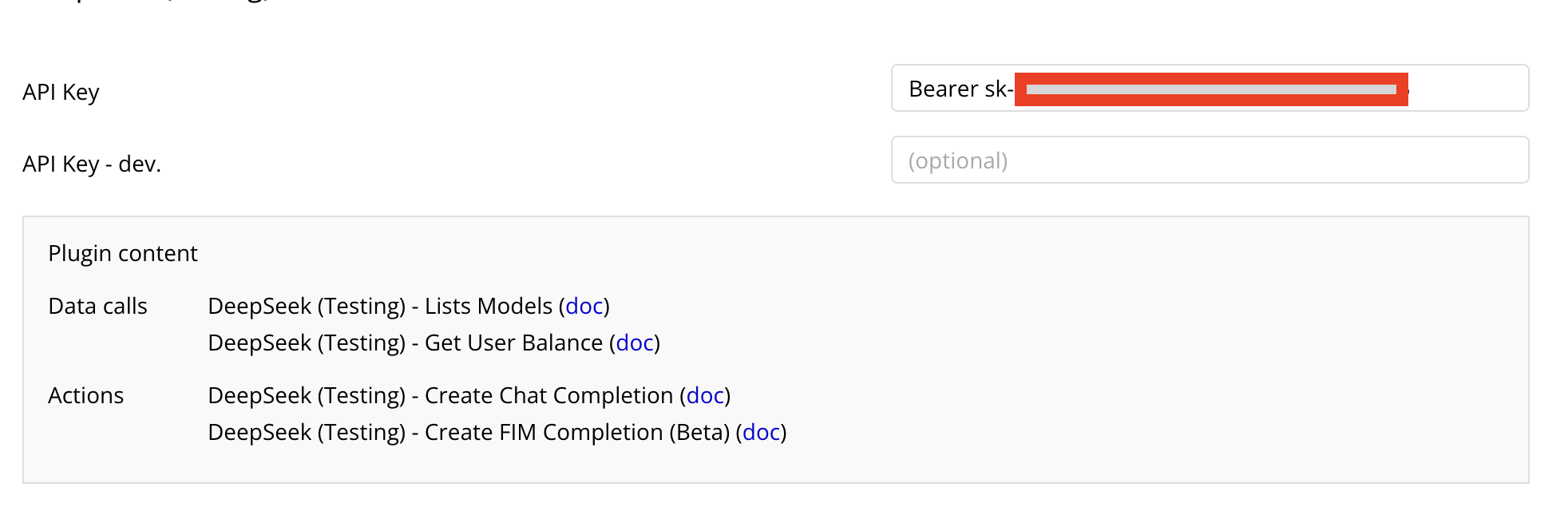
The plugin has 4 API calls. To work with them, you must specify the API key in the plugin settings.
Let’s go over in more detail how to obtain the API key
- We need to register on this page - https://platform.deepseek.com/sign_in
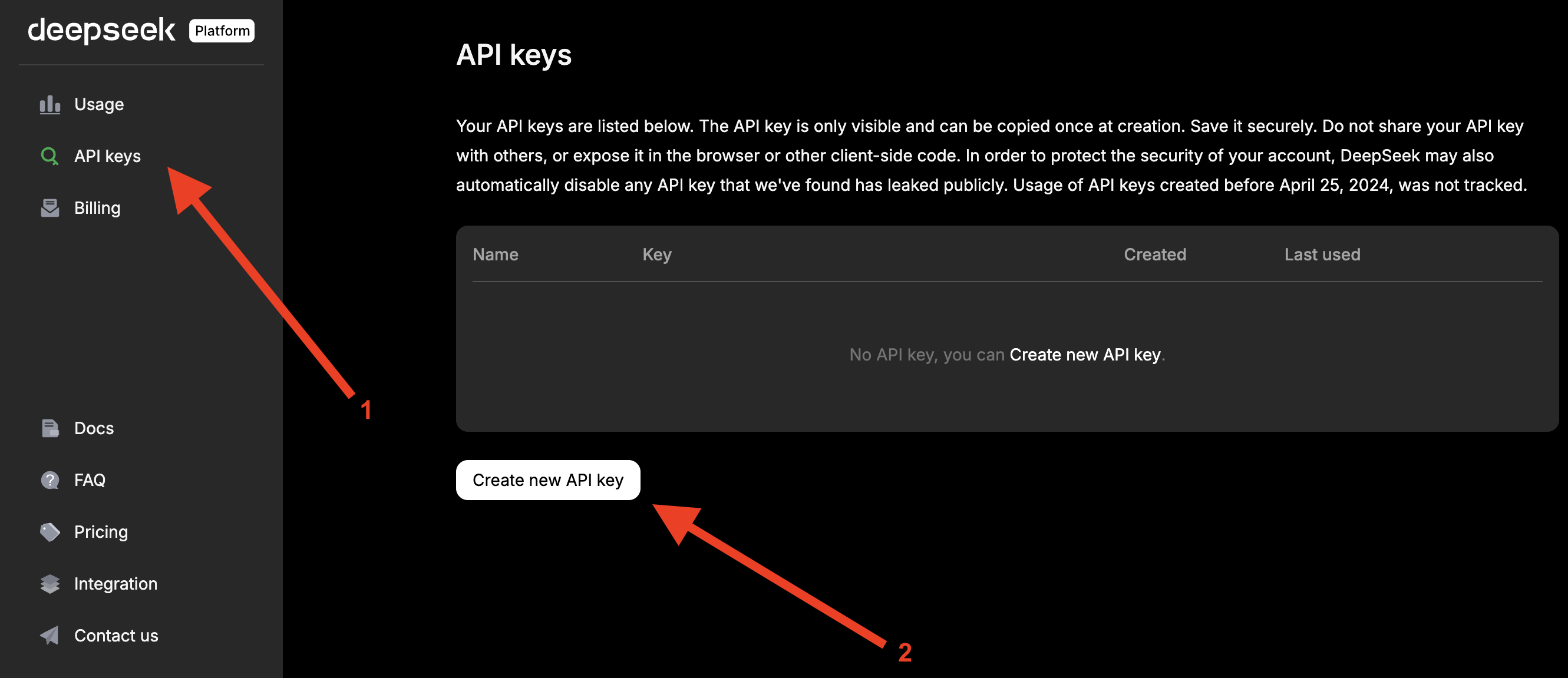
- Now let's create an api key - https://platform.deepseek.com/api_keys
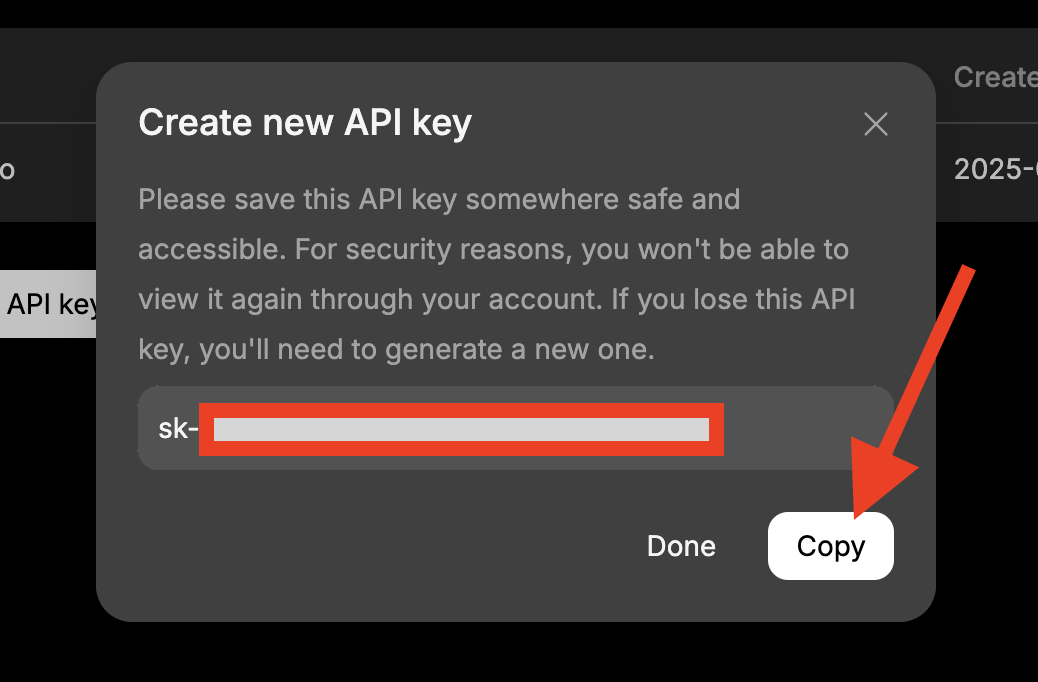
- You need to copy the created api key and paste it into the plugin settings
- We need to fund our account so we can use DeepSeek.
Plugin Data Calls
Lists Models
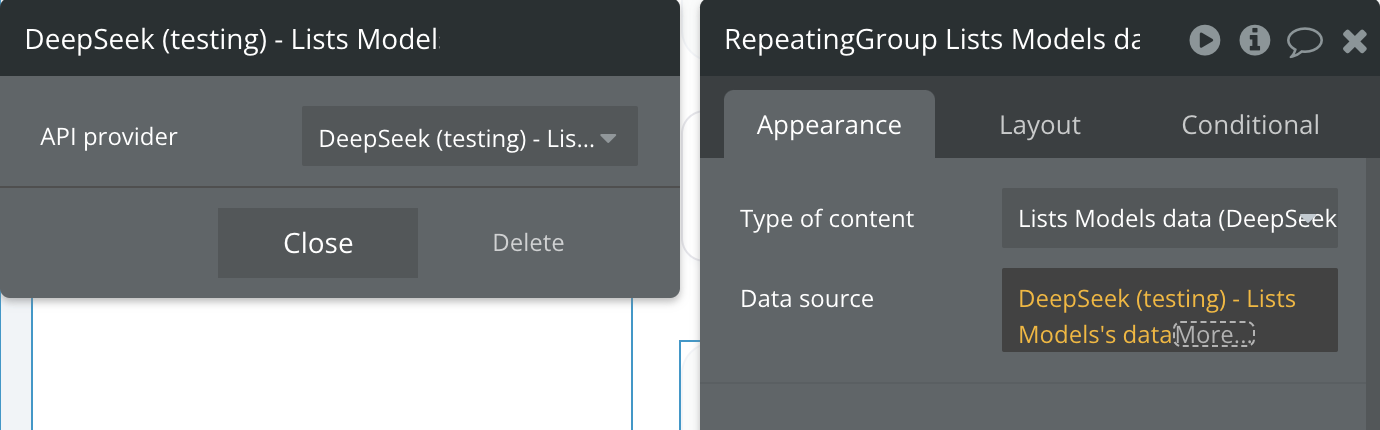
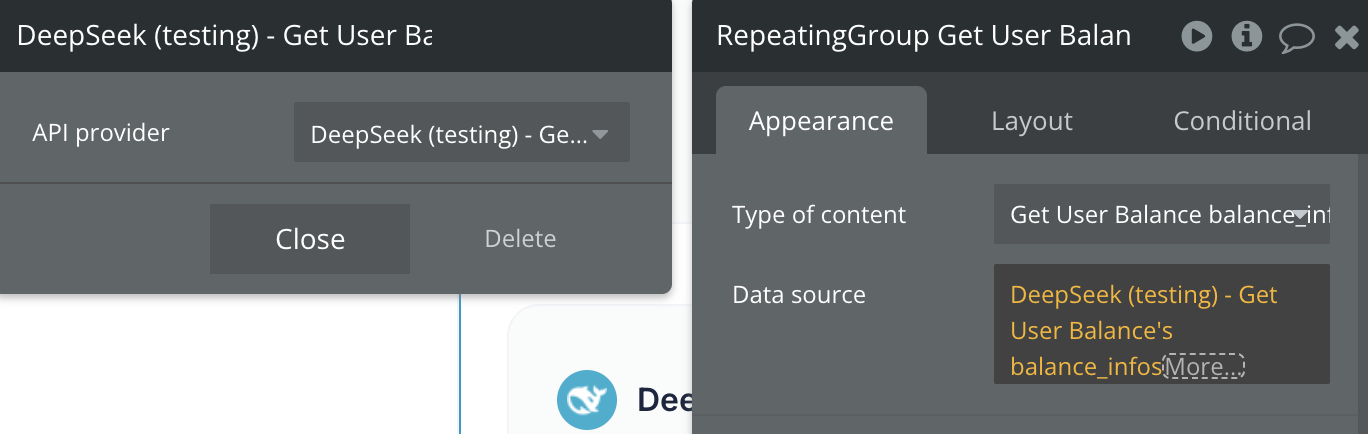
Get User Balance
Plugin Action Calls
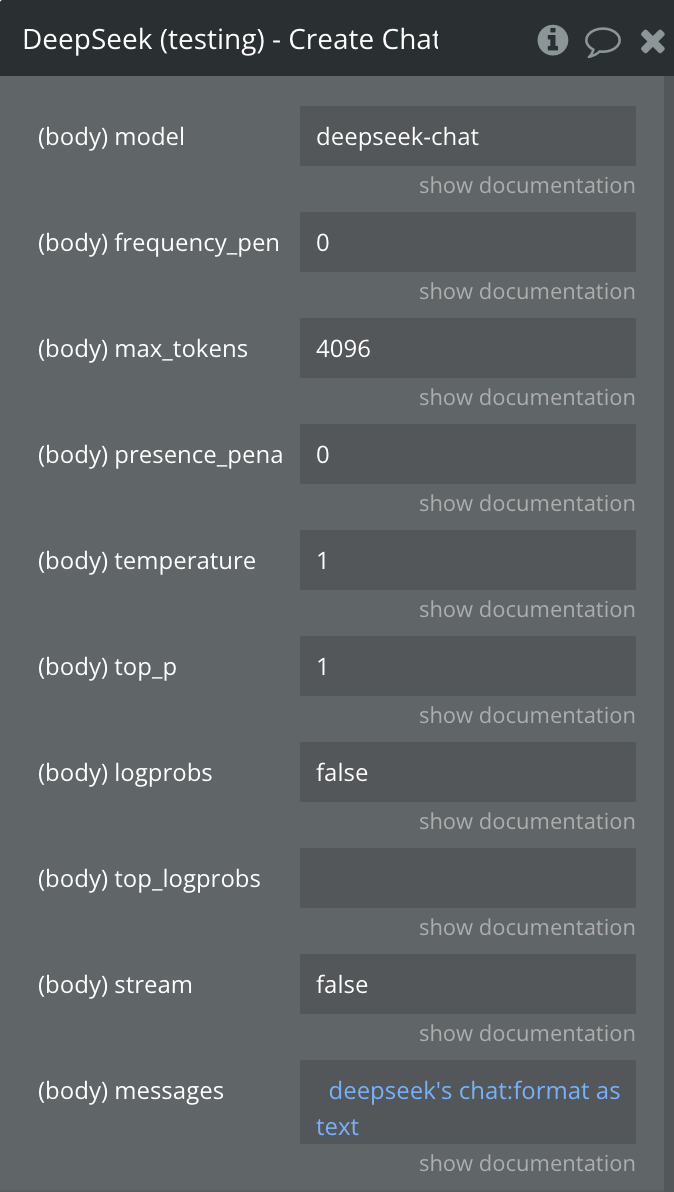
Create Chat Completion
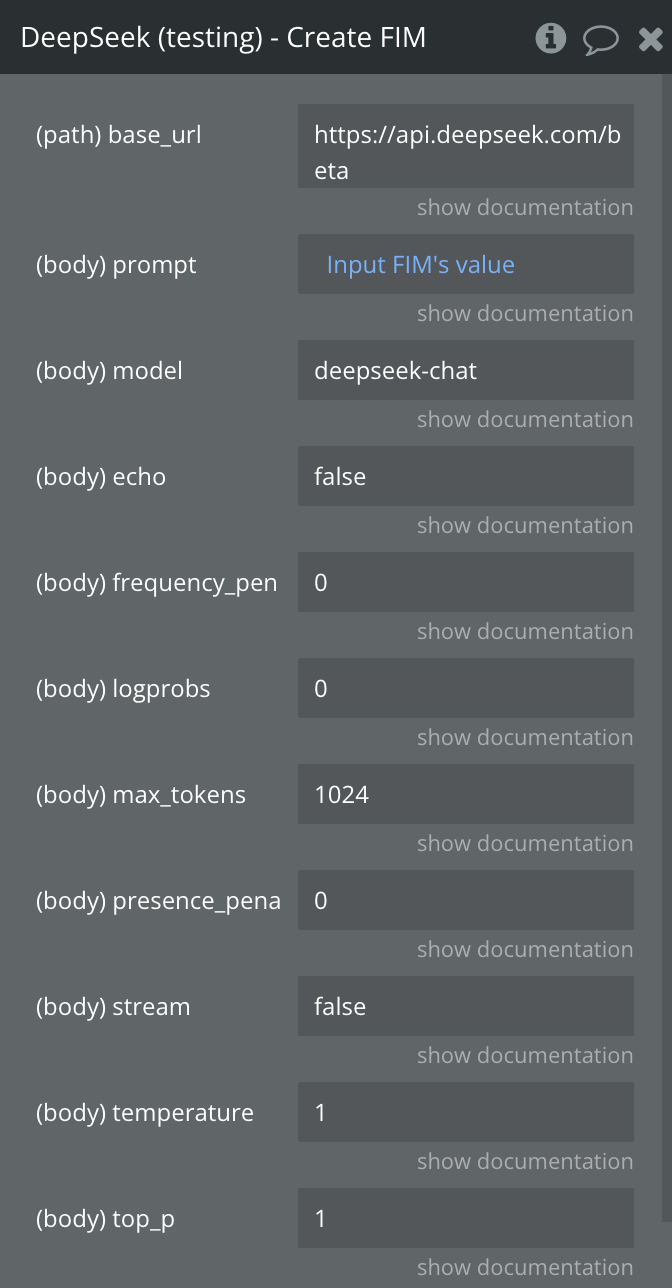
Create FIM Completion (Beta)