Demo to preview the settings
Introduction
Natural Language uses machine learning to reveal the structure and meaning of text. You can extract information about people, places, and events, and better understand social media sentiment and customer conversations.
Prerequisites
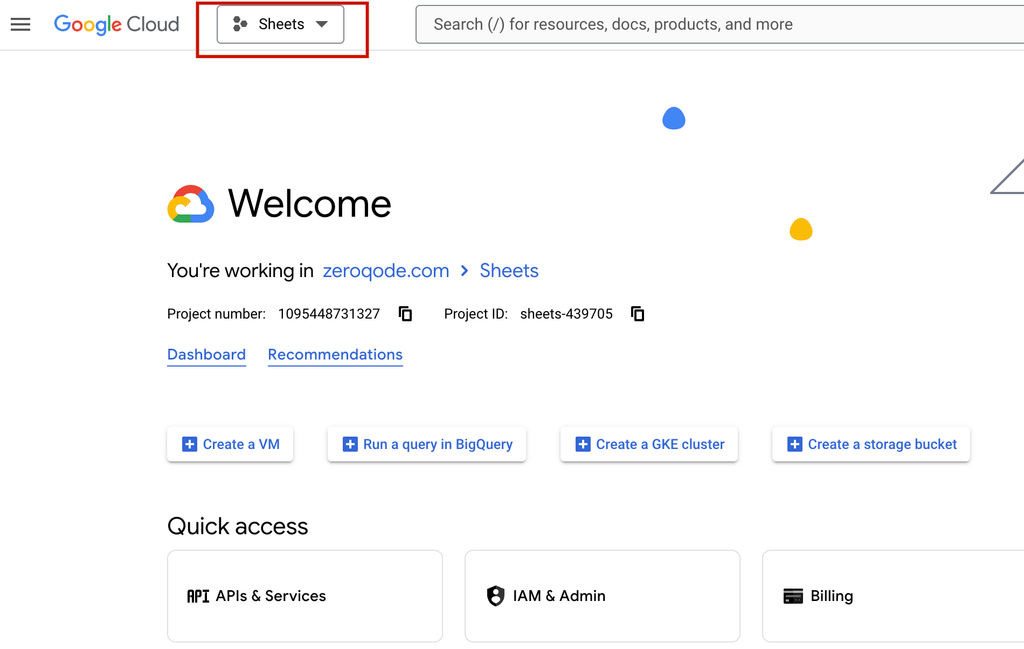
1. Set Up Google Cloud Project
- Go to the Google Cloud Console: Open Google Cloud Console.
- Sign in: Log in to your Google account if you haven’t already.
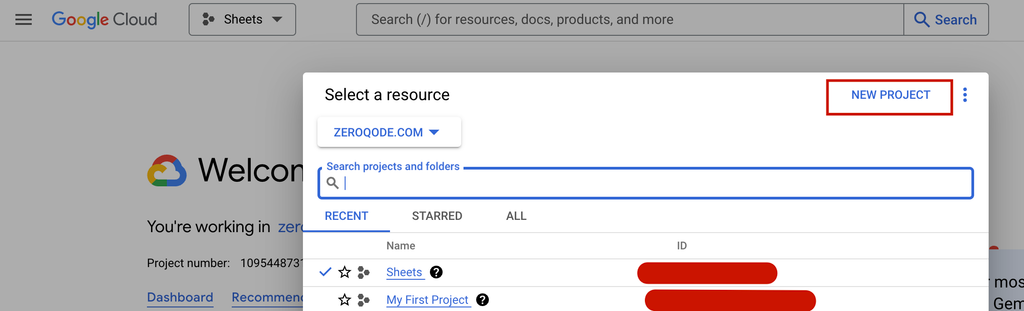
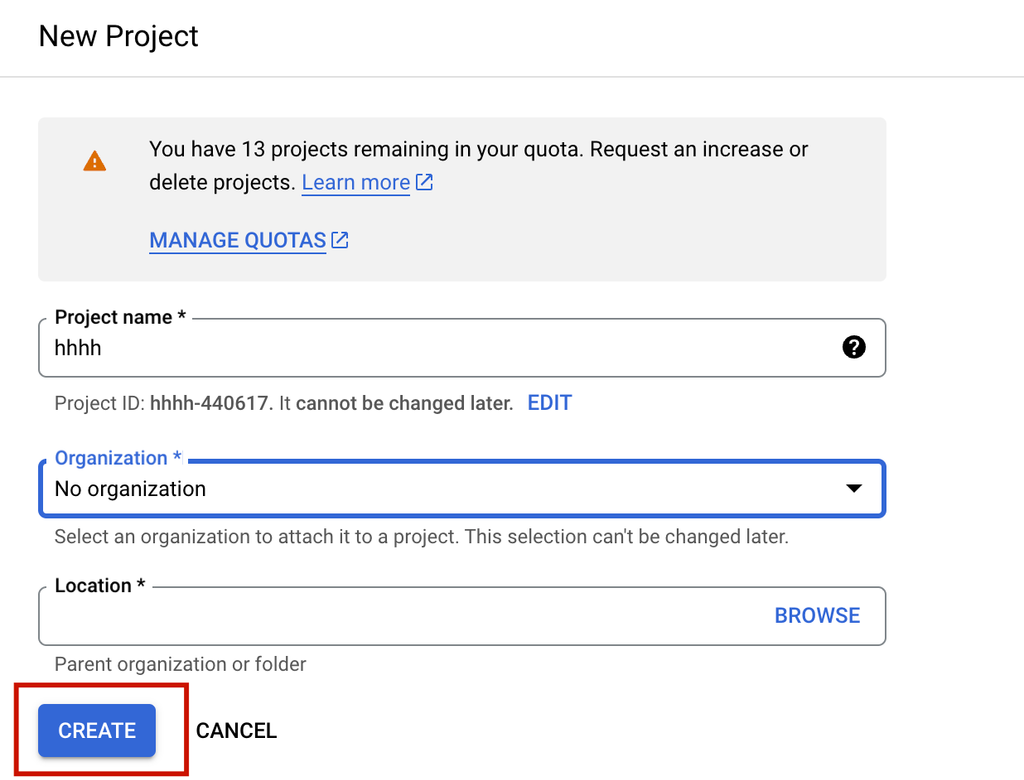
- Create a New Project:
- In the top navigation, click on the Project Dropdown menu.
- Click New Project.
- Enter a project name (e.g., "Sentiment Analysis Project").
- Select your organization or billing account if required.
- Click Create.
2. Enable the Natural Language API
- Navigate to the API Library:
- In the left sidebar, go to APIs & Services > Library.
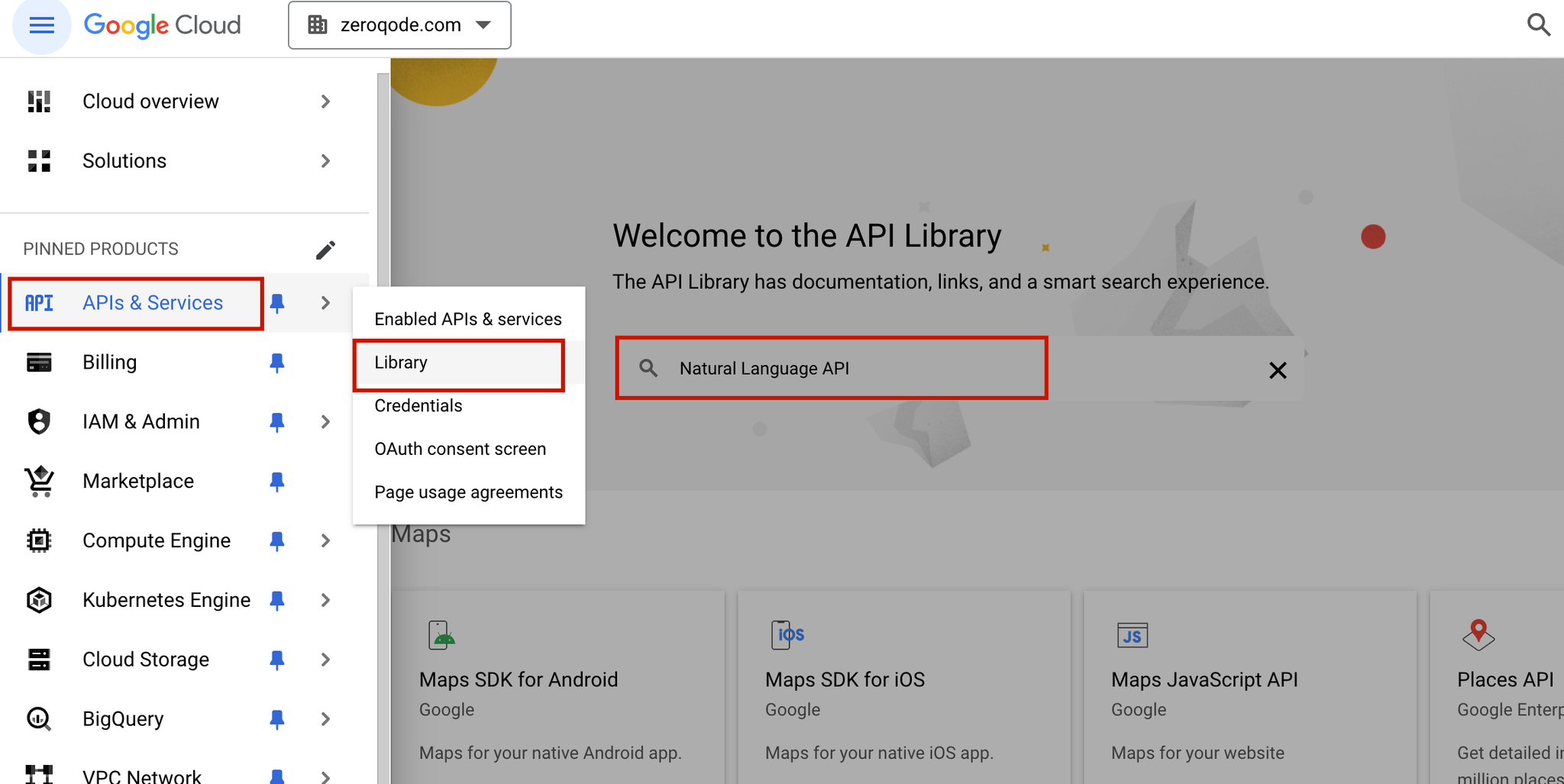
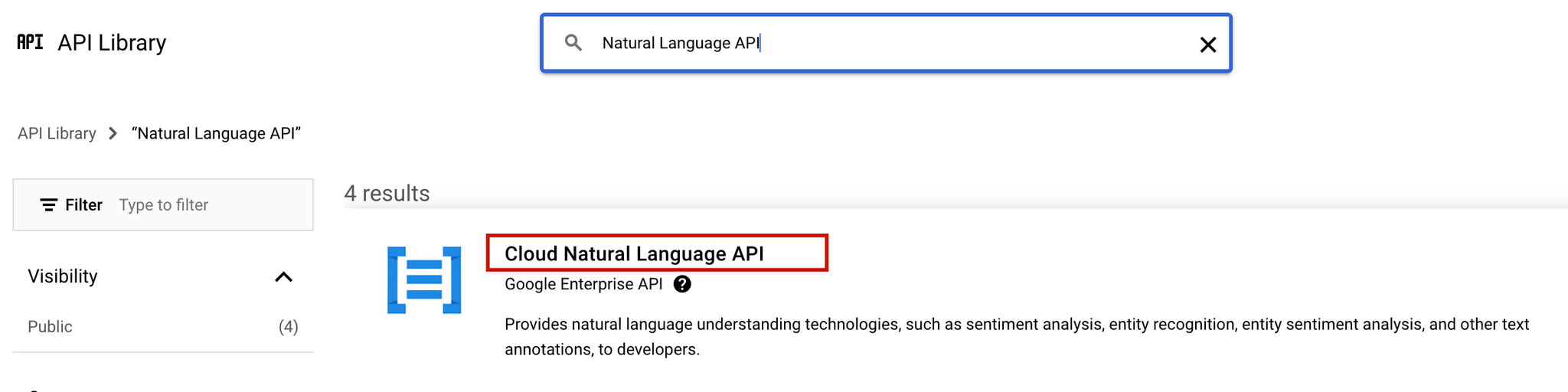
- Find and Enable the Natural Language API:
- In the search bar, type Natural Language API.
- Click on Google Cloud Natural Language API in the results.
- Click Enable.
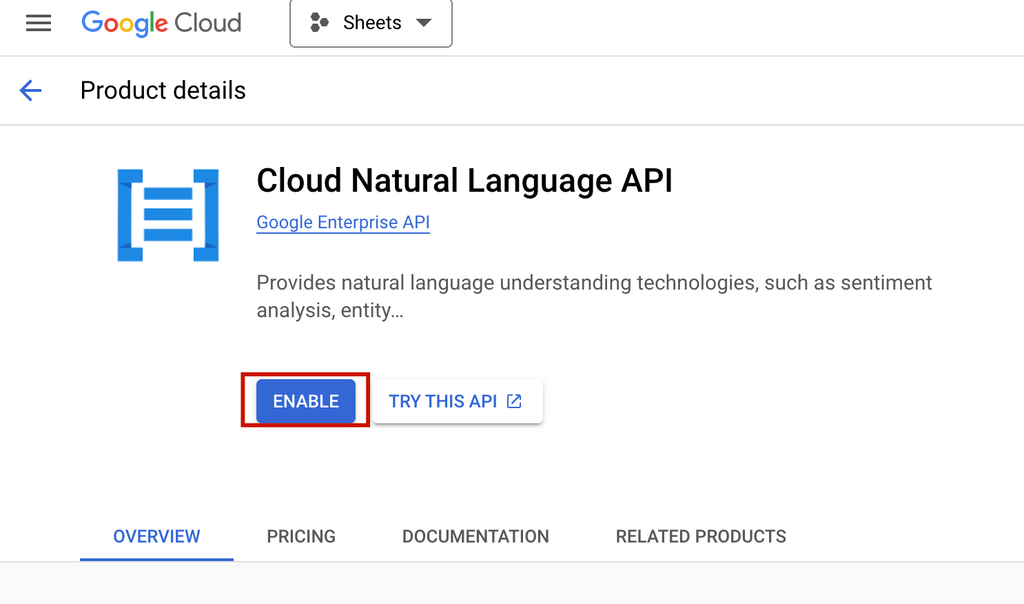
3. Create an API Key
- Go to Credentials:
- In the left sidebar, go to APIs & Services > Credentials.
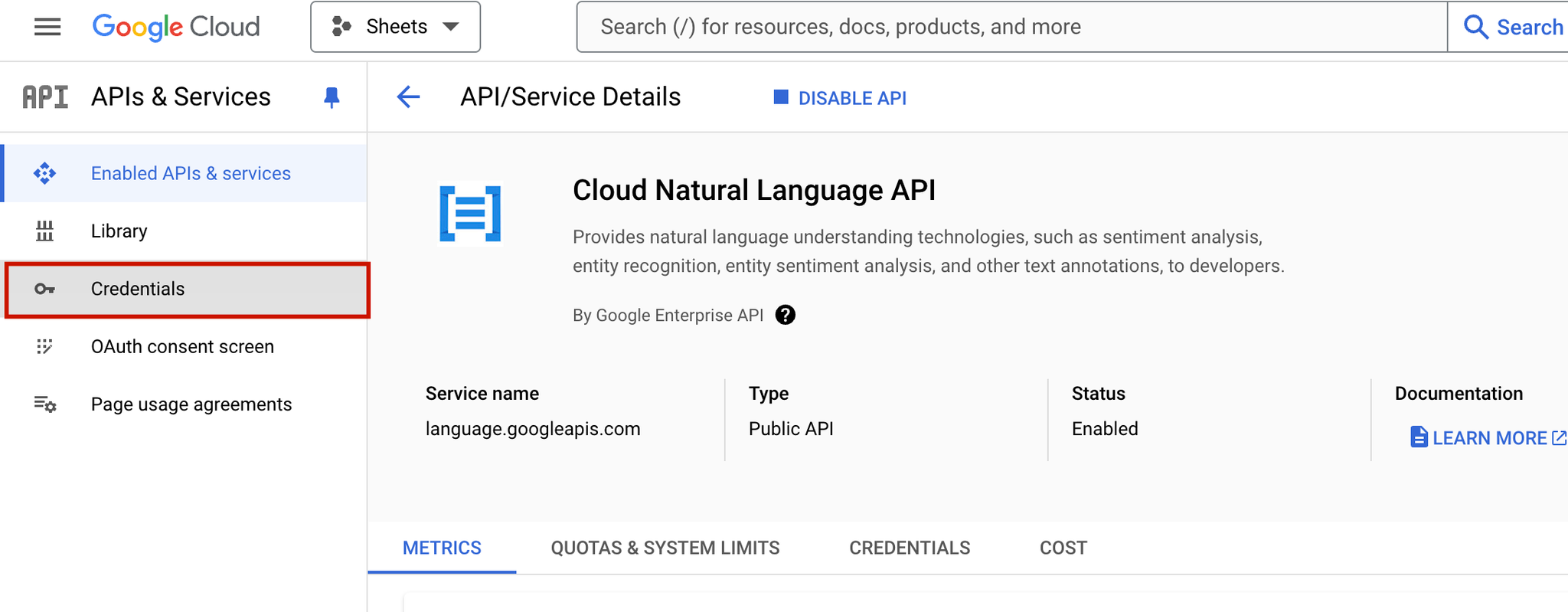
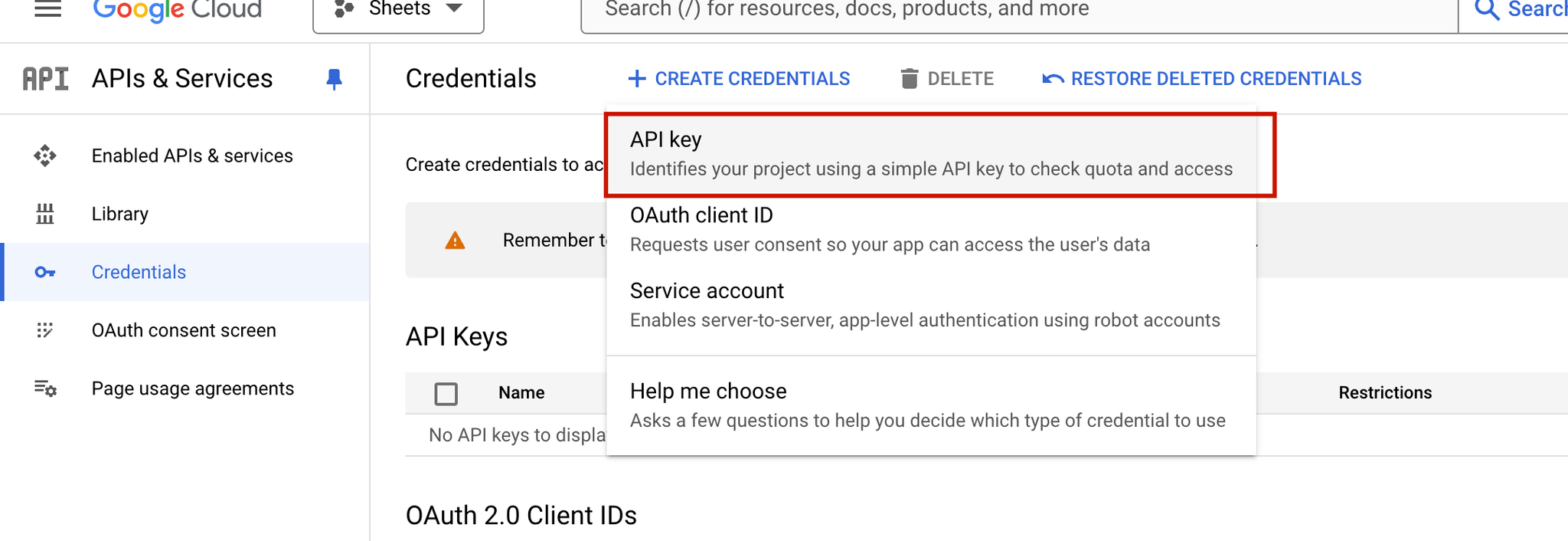
- Create Credentials:
- Click Create Credentials at the top and select API Key.
- Google will generate a new API key. Copy this key for later use in the plugin settings.
4. Configure Your Plugin with the API Key
- Enter the API Key in your application settings.
How to setup
- Install the plugin
- Set up the API Key in plugin settings
Plugin Data Calls
Analyze Entities
Finds named entities (currently proper names and common nouns) in the text along with entity types, salience, mentions for each entity, and other properties.
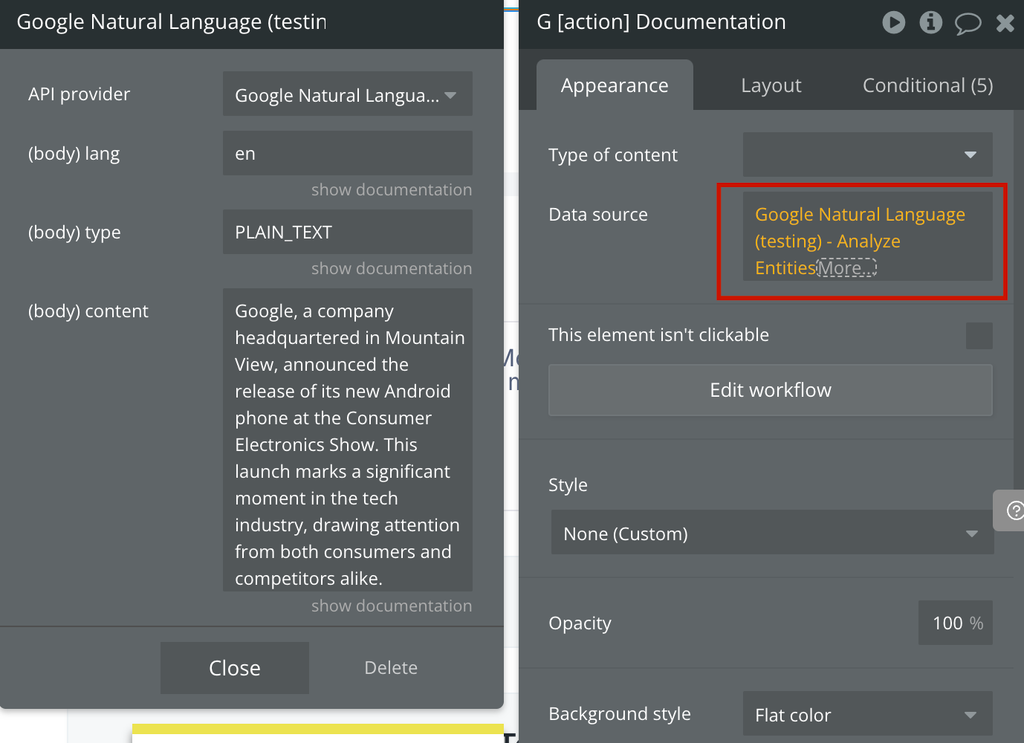
Fields:
Title | Description | Type |
lang | Language of the text content to be analyzed, using ISO 639-1 code format (e.g., "en" for English). | Text |
type | Type of content, specifying how the content is provided. Options include "PLAIN_TEXT" (for text content) and "HTML" (for HTML content). | Text |
content | The actual text content for analysis. This can be the raw text or HTML, depending on the type specified. | Text |
Analyze Entity Sentiment
Identifies entities (like people, places, and organizations) in text and analyzes the sentiment expressed towards each entity. It returns details on each entity's sentiment (positive, negative, or neutral), allowing for deeper insights into opinions and attitudes within the content.
Fields:
Title | Description | Type |
lang | Language of the text content to be analyzed, using ISO 639-1 code format (e.g., "en" for English). | Text |
type | Type of content, specifying how the content is provided. Options include "PLAIN_TEXT" (for text content) and "HTML" (for HTML content). | Text |
content | The text content for which entity sentiment analysis will be performed. This can be raw text or HTML, depending on the specified type. | Text |
Analyze Sentiment
Examines the overall sentiment expressed in a text document, identifying positive, negative, or neutral tones and providing sentiment scores and magnitudes. This can help assess the general emotional content of text.
Fields:
Title | Description | Type |
lang | Language of the text content to be analyzed, using ISO 639-1 code format (e.g., "en" for English). | Text |
type | Type of content, specifying how the content is provided. Options include "PLAIN_TEXT" (for text content) and "HTML" (for HTML content). | Text |
content | The actual text content to be analyzed for sentiment. This can be either raw text or HTML, depending on the type specified. | Text |
Analyze Syntax
Analyzes the grammatical structure of a text document, identifying tokens (such as words and punctuation), parts of speech, lemmas, and syntactic relationships (like subject, object, etc.). This API is useful for understanding the linguistic structure of text.
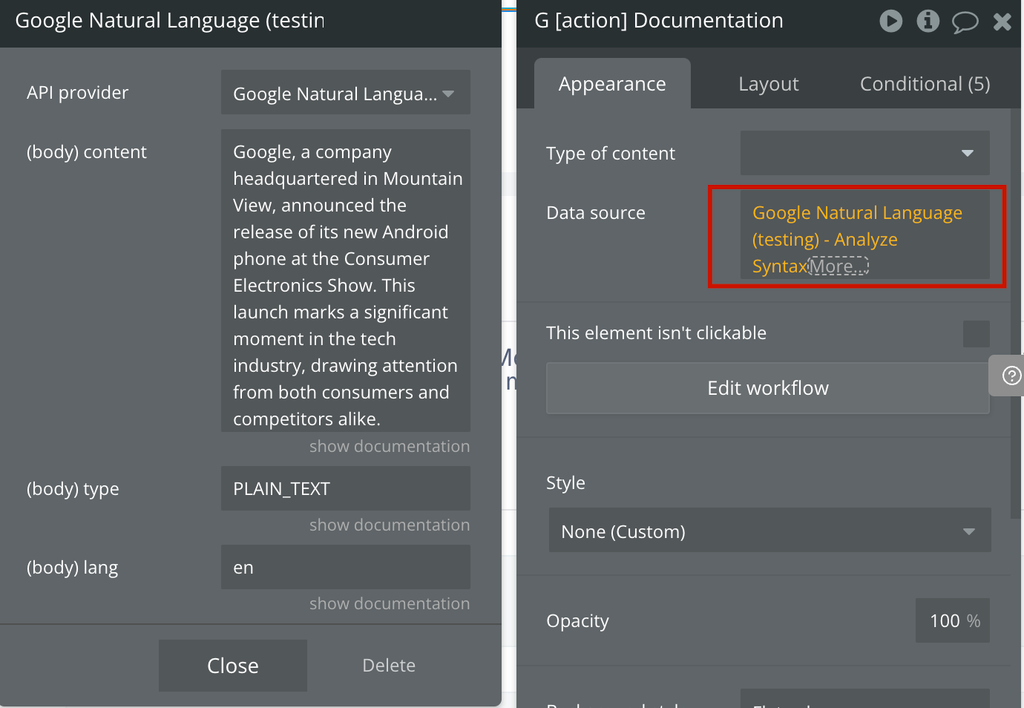
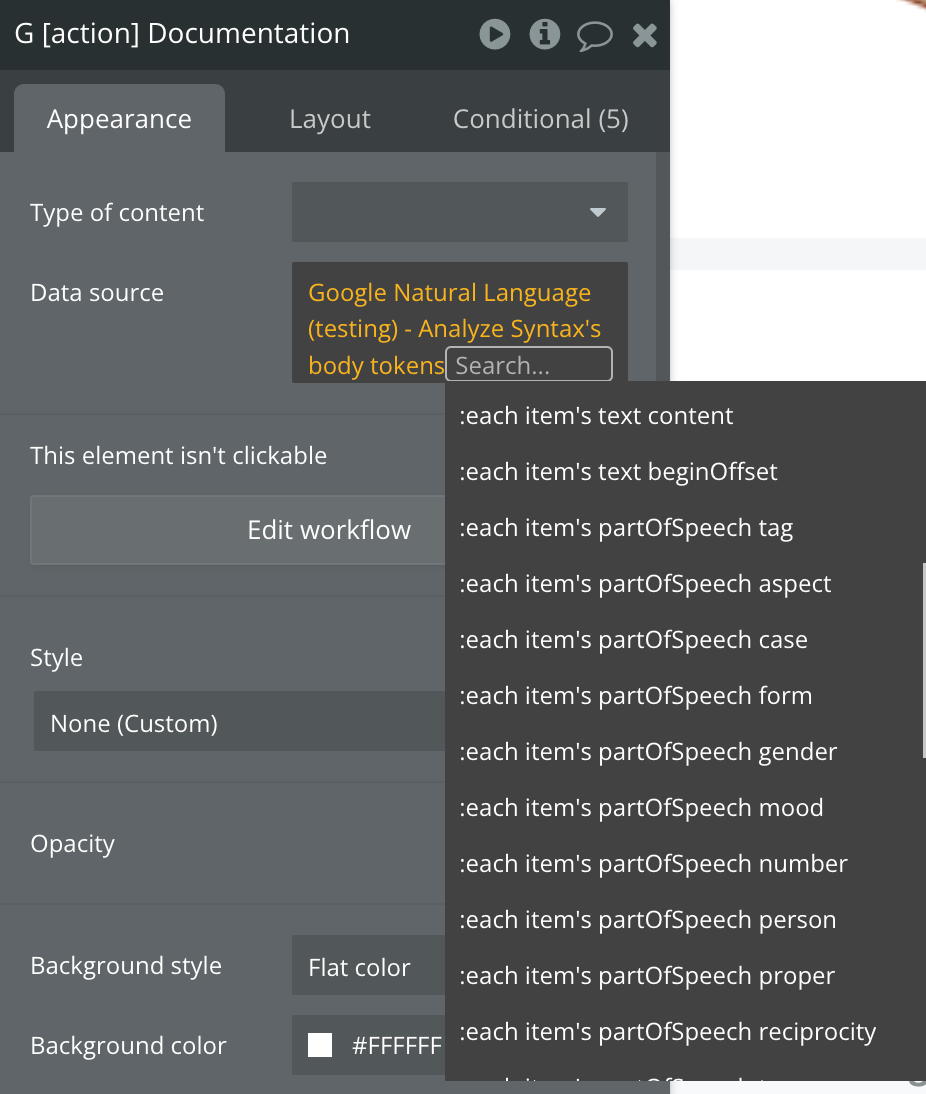
Fields:
Title | Description | Type |
lang | Language of the text content to be analyzed, using ISO 639-1 code format (e.g., "en" for English). | Text |
type | Type of content, specifying how the content is provided. Options include "PLAIN_TEXT" (for text content) and "HTML" (for HTML content). | Text |
content | The text content to be analyzed for syntax. This can be raw text or HTML, depending on the specified type. | Text |
Annotate Text
Identifies entities (like people, places, and organizations) in text and analyzes the sentiment expressed towards each entity. It returns details on each entity's sentiment (positive, negative, or neutral), allowing for deeper insights into opinions and attitudes within the content.
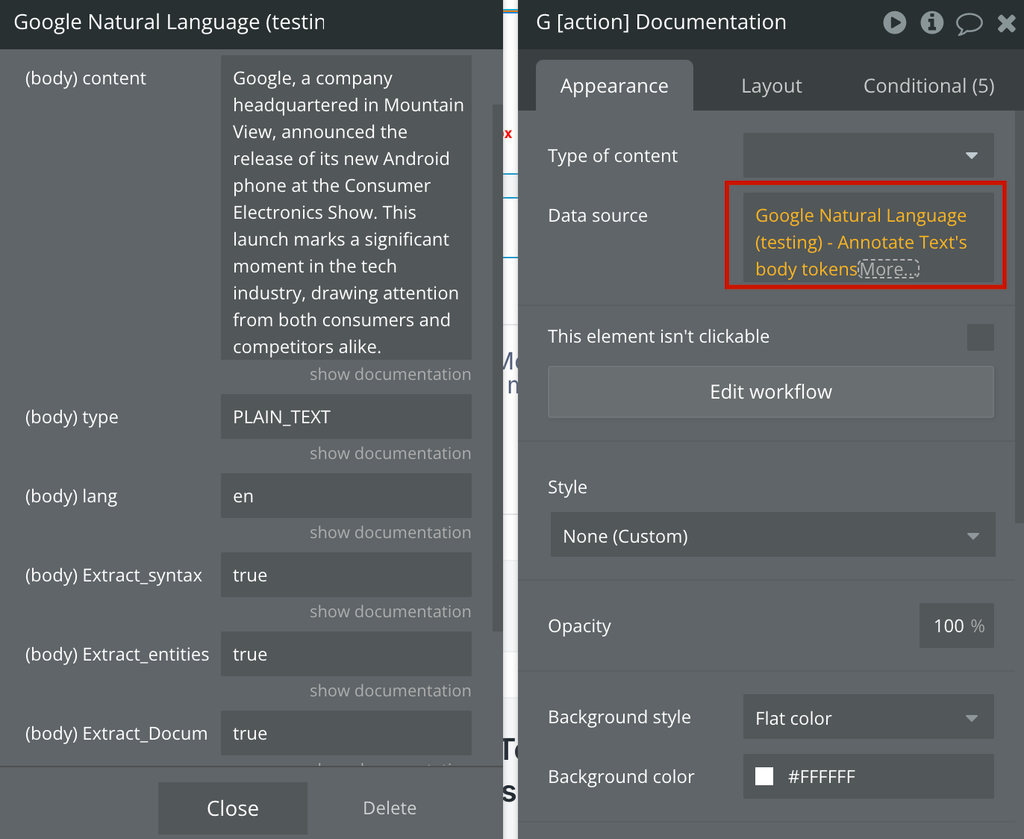
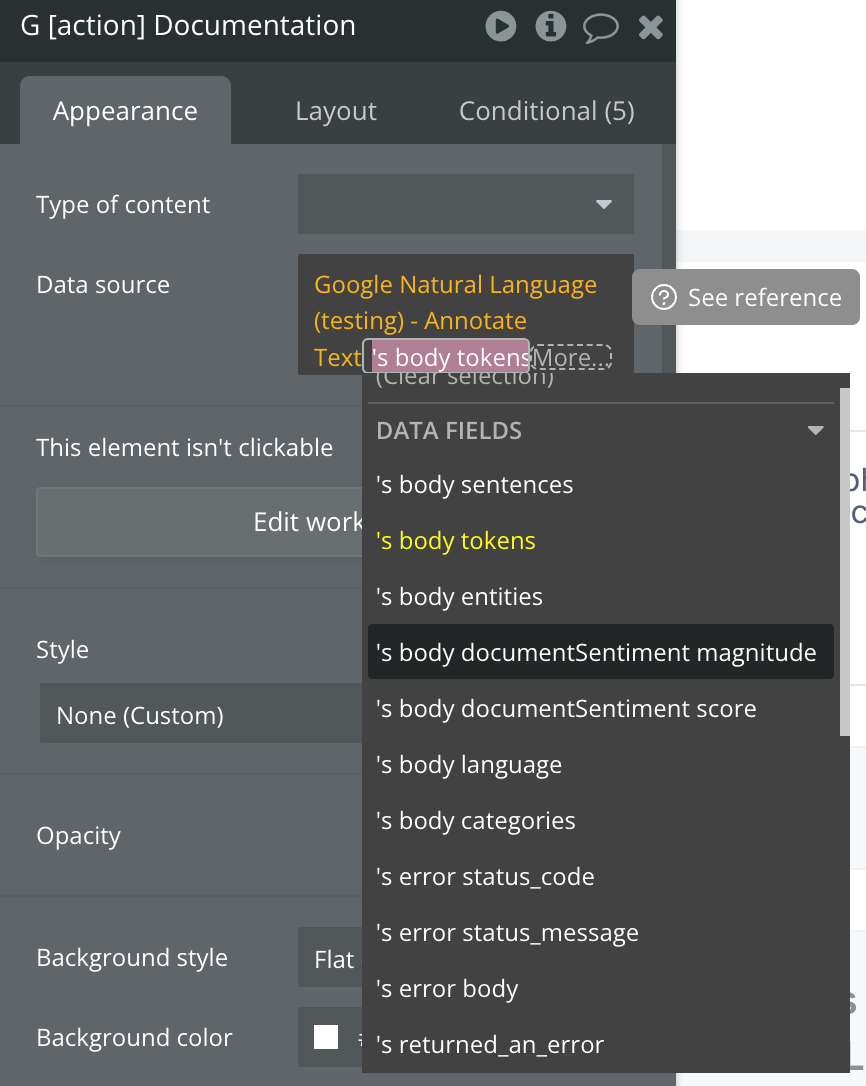
Fields:
Title | Description | Type |
content | The actual text content for analysis. This can be either raw text or HTML, based on the type specified. | Text |
type | Defines the format of the content. Options are "PLAIN_TEXT" for plain text or "HTML" for HTML content, indicating how the content will be processed. | Text |
lang | Specifies the language of the text using ISO 639-1 codes (e.g., "en" for English). | Text |
Extract_syntax | Defines whether to analyze the grammatical structure (syntax) of the text. When true, the response will contain the grammatical analysis of the text. | Text ( true/false ) |
Extract_entities | Defines whether to recognize entities (like people, places, and organizations) within the text. When true, the response will include identified entities. | Text ( true/false ) |
Extract_Document_sentiment | Defines whether to assess the overall sentiment of the entire document. When true, the response will contain the document's sentiment score and magnitude. | Text ( true/false ) |
Extract_Entity_sentiment | Defines whether to analyze sentiment specifically associated with each identified entity. When true, the response will include sentiment details for each entity in the text. | Text ( true/false ) |
Classify_text | Defines whether to categorize the content into predefined categories. When true, the response will contain the text's category labels (requires a certain minimum content length and may only support certain languages). | Text ( true/false ) |
Classify Text
Categorizes the content of a text document into predefined categories, providing high-level topic insights. This API is particularly useful for understanding the main subjects of a text.
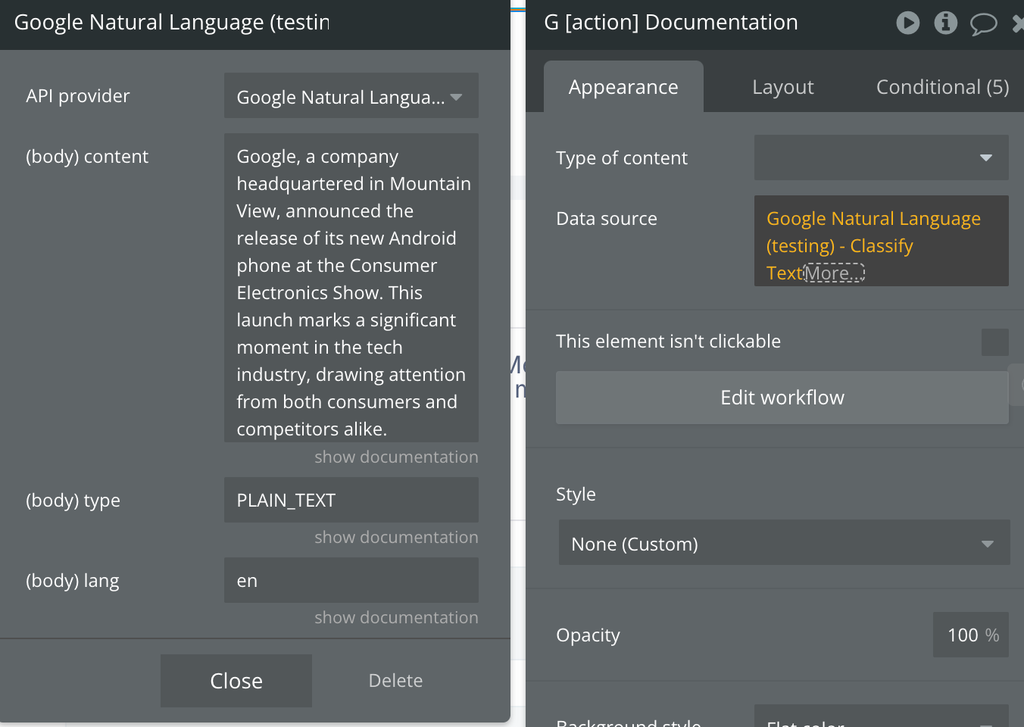
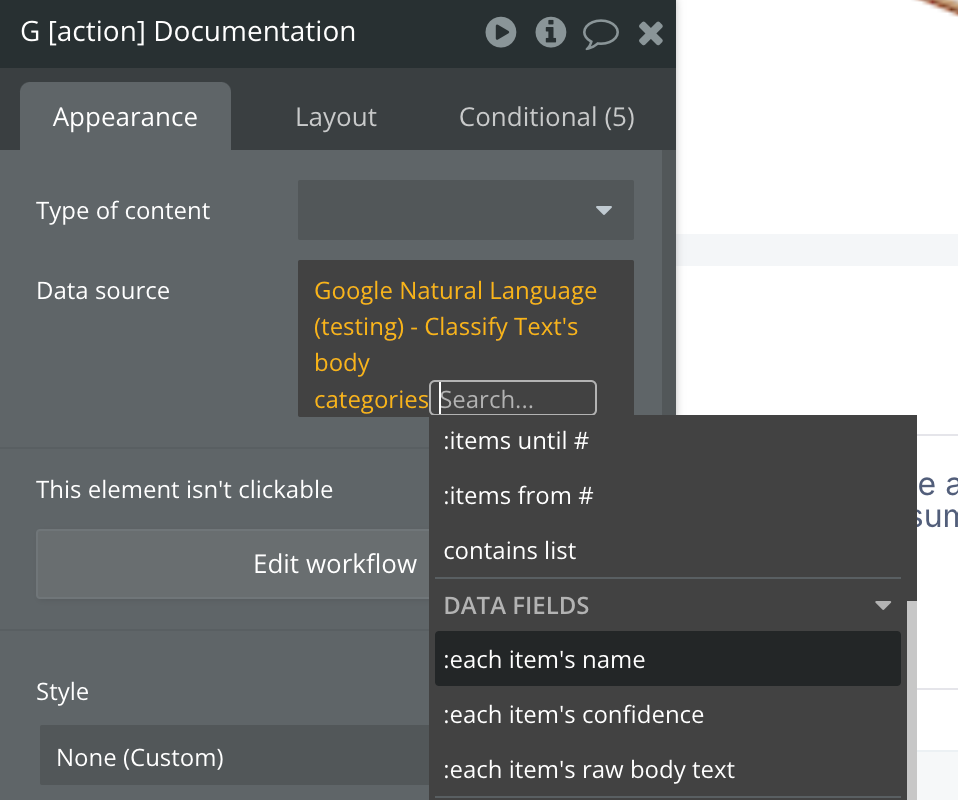
Fields:
Title | Description | Type |
content | Contains the actual text content to be classified. When provided, this can be either raw text or HTML, depending on the specified type. | Text |
type | Defines the format of the content. Options include "PLAIN_TEXT" for plain text and "HTML" for HTML content. When set, this indicates how the content should be processed. | Text |
lang | Defines the language of the text, using ISO 639-1 codes (e.g., "en" for English). | Text |