Demo to preview the plugin:
Introduction
Add voice interaction to your Bubble app with ease using the Speech Capabilities Plugin. Powered by the Web Speech API, this plugin introduces Text-to-Speech (TTS) and Speech Recognition (SR) functionalities, enabling your app to speak to users and listen to them in real time. With extensive customization options and real-time transcription, you can build immersive, accessible, and interactive user experiences.
Key Features
Prerequisites
- Ensure your users are on modern browsers (Chrome, Edge, Safari) for best support.
- Have a basic understanding of how to use workflows and elements in Bubble.
- No API key is needed as this relies on native browser functionality.
Note: These features are experimental and browser-dependent. Check compatibility on caniuse.com.
How to setup
Step 1: Installation
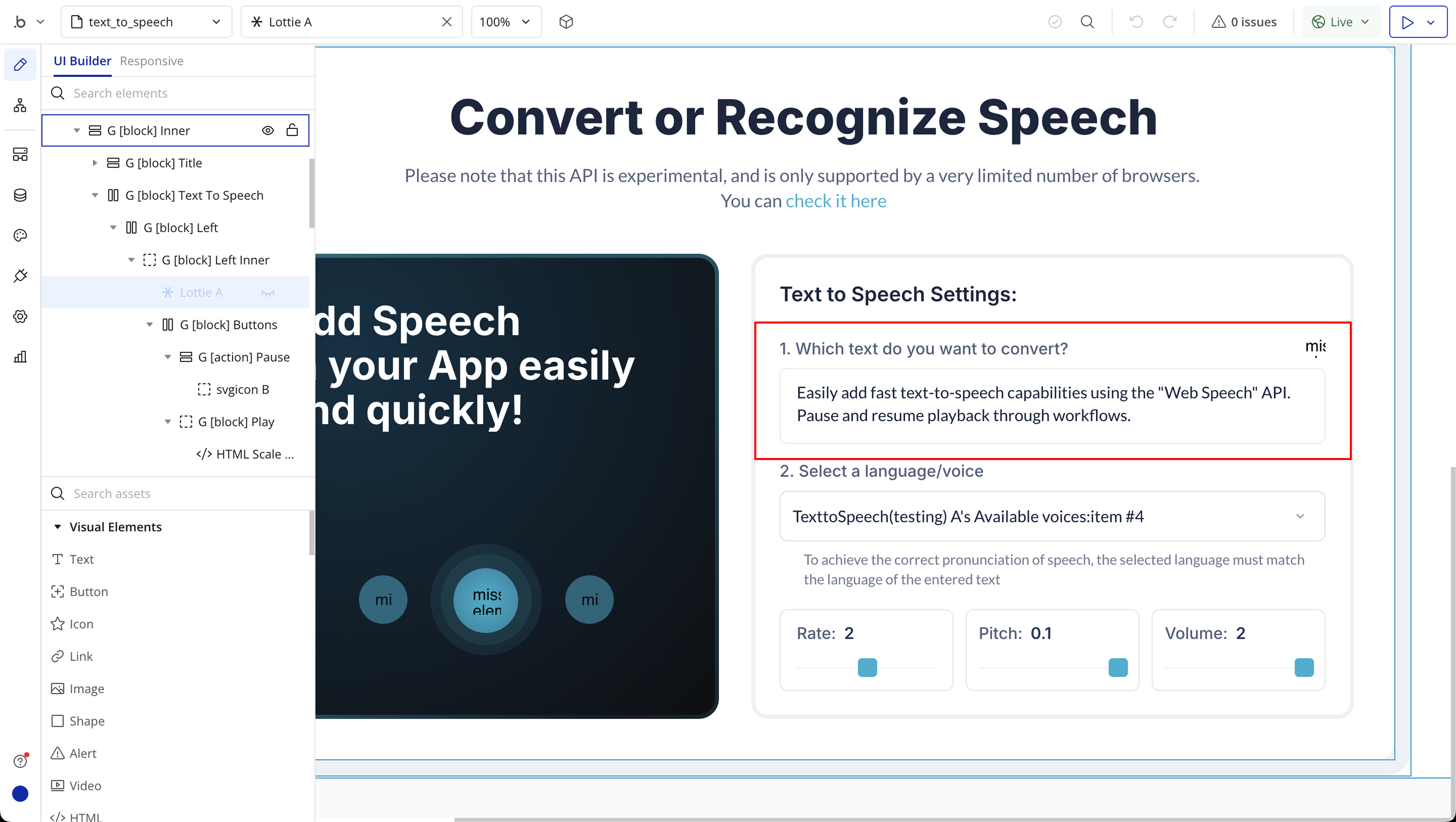
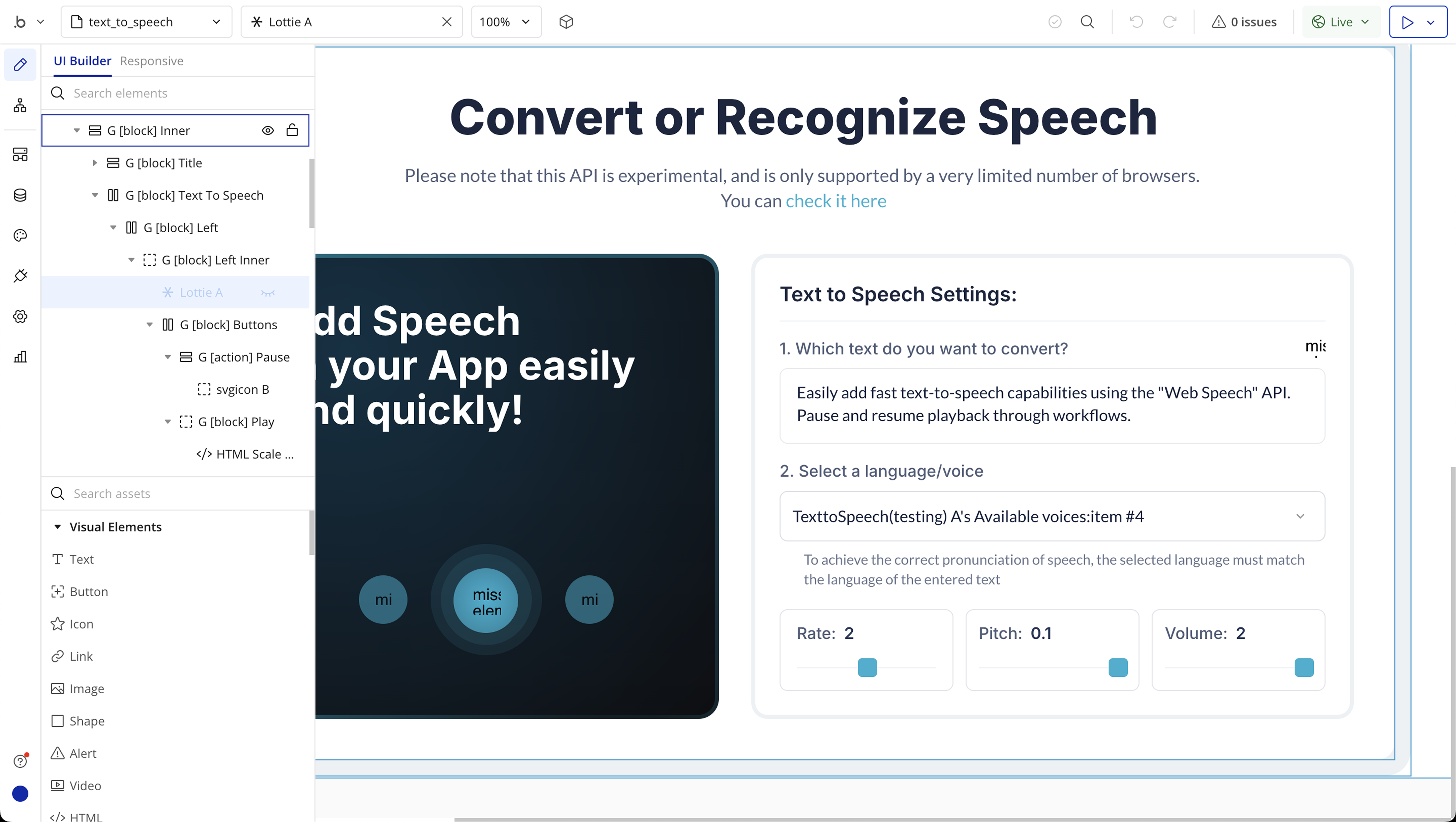
Step 2: Place the Element (Text to Speech)
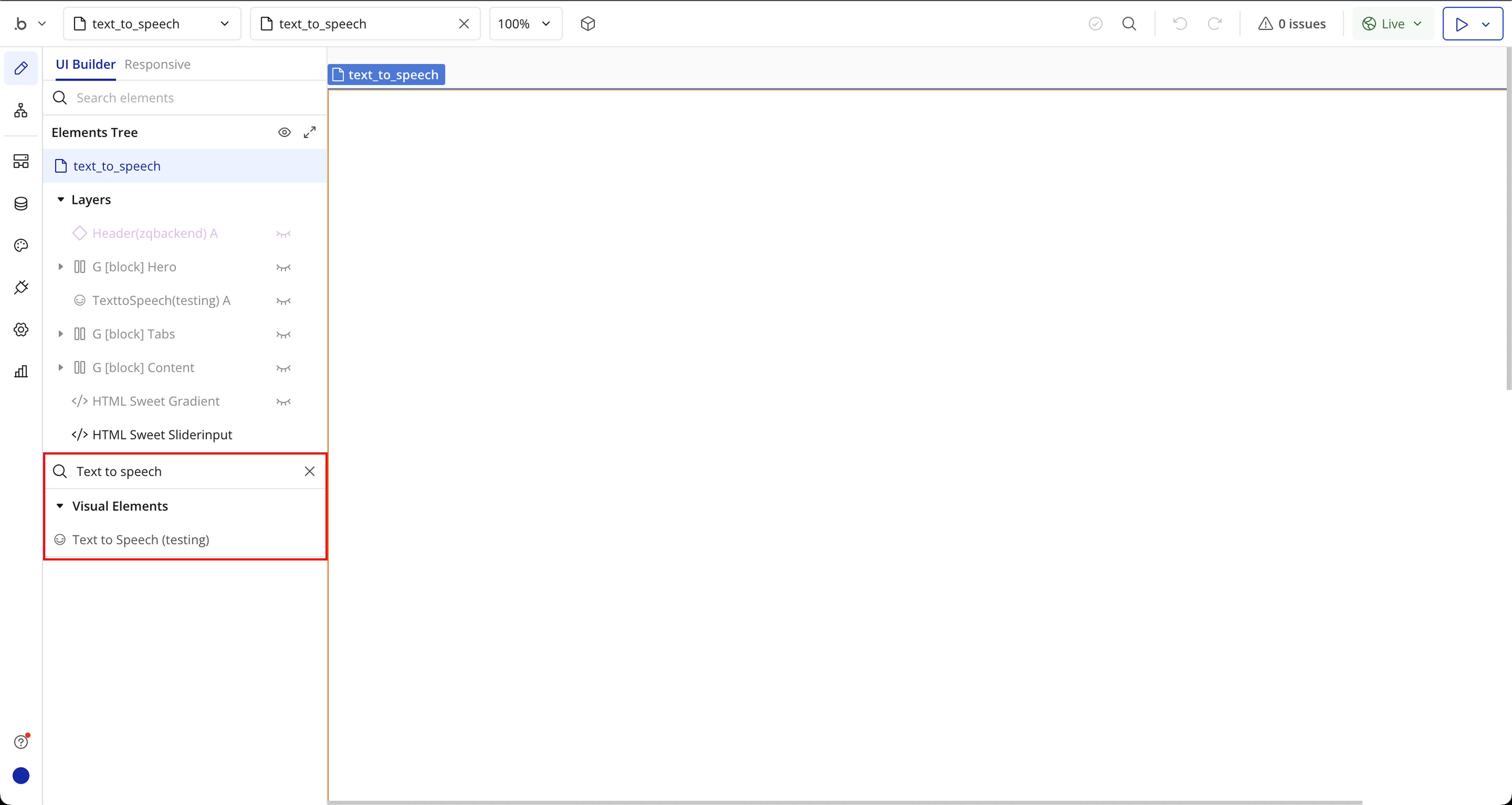
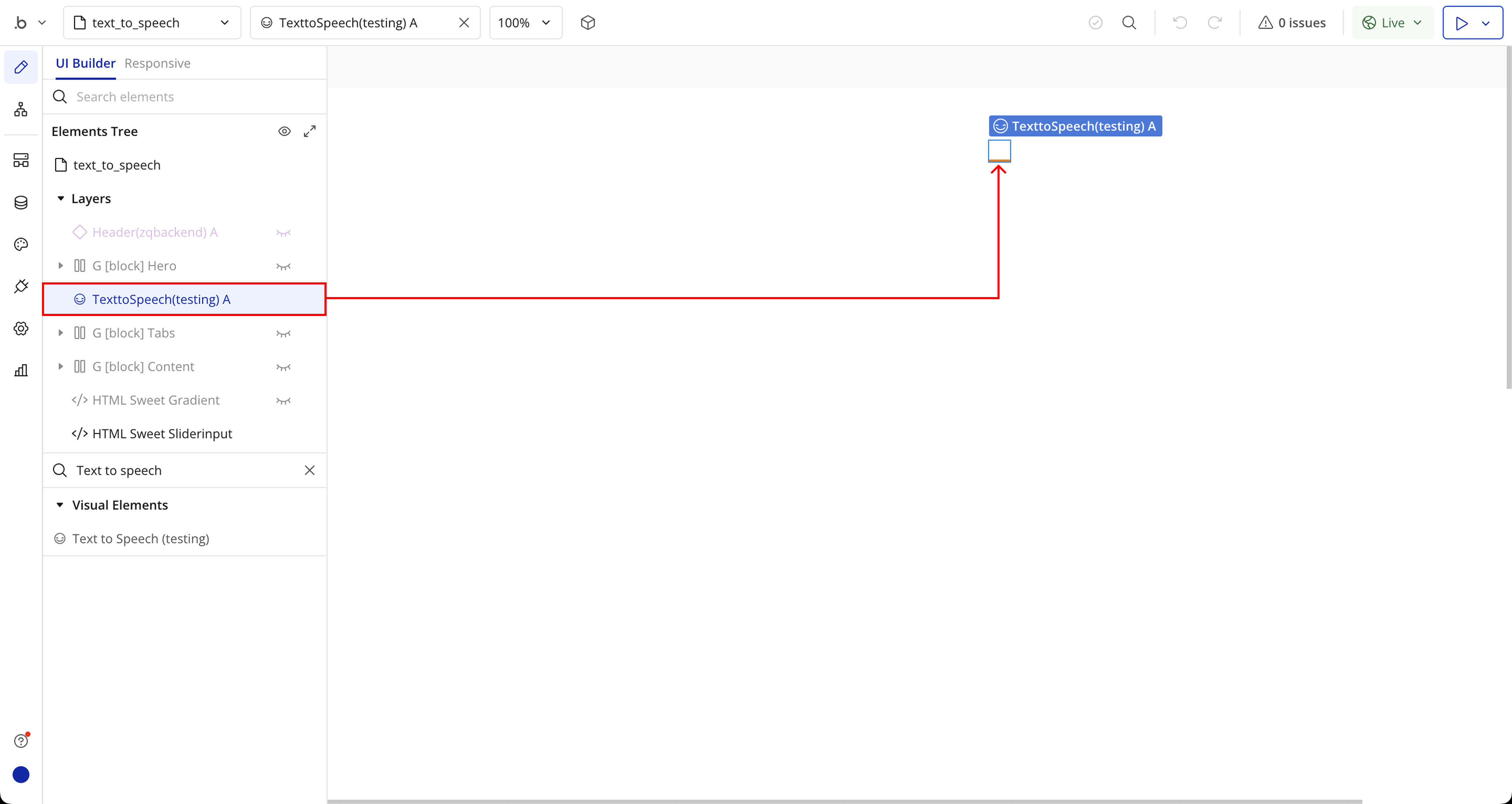
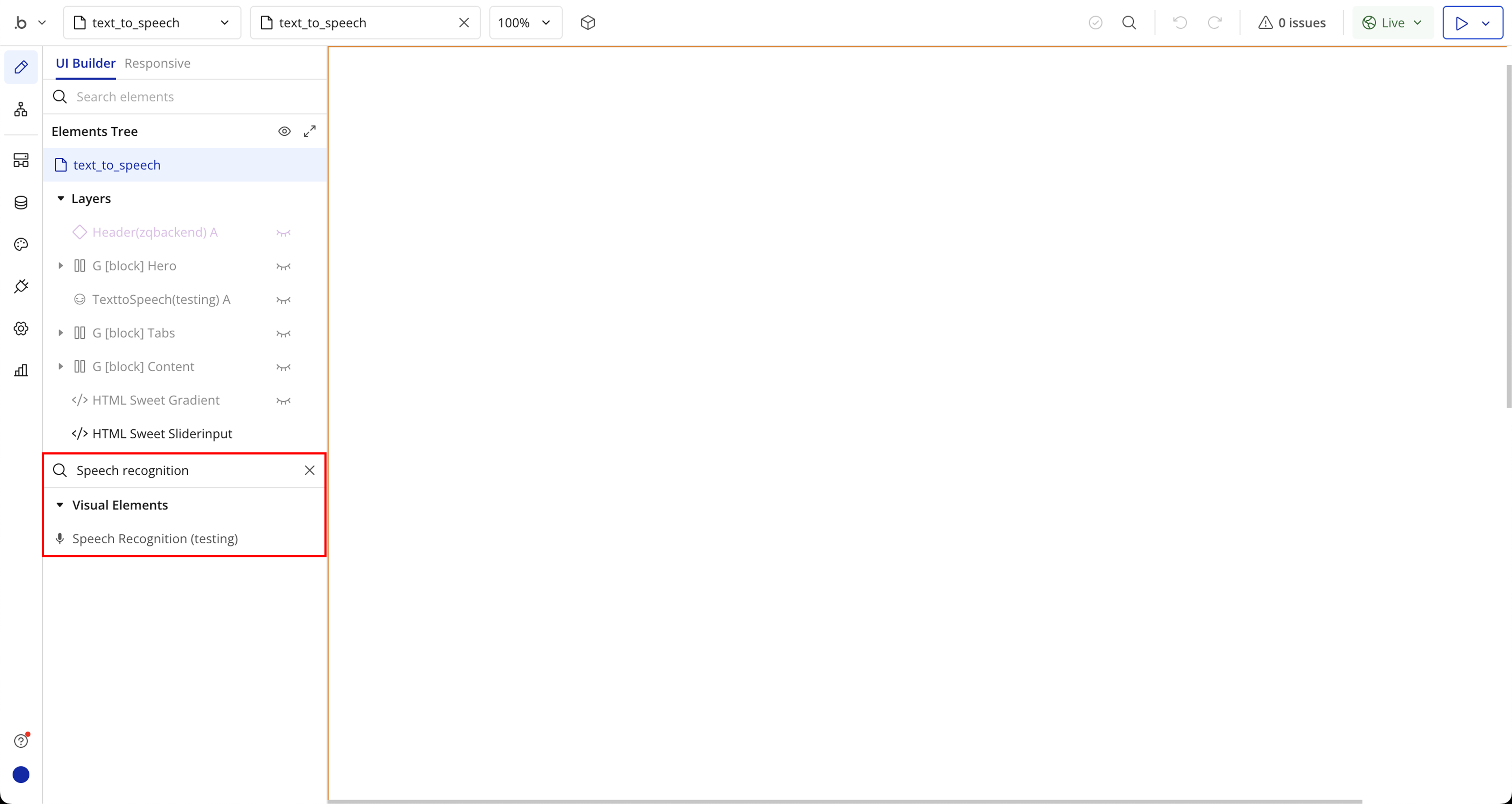
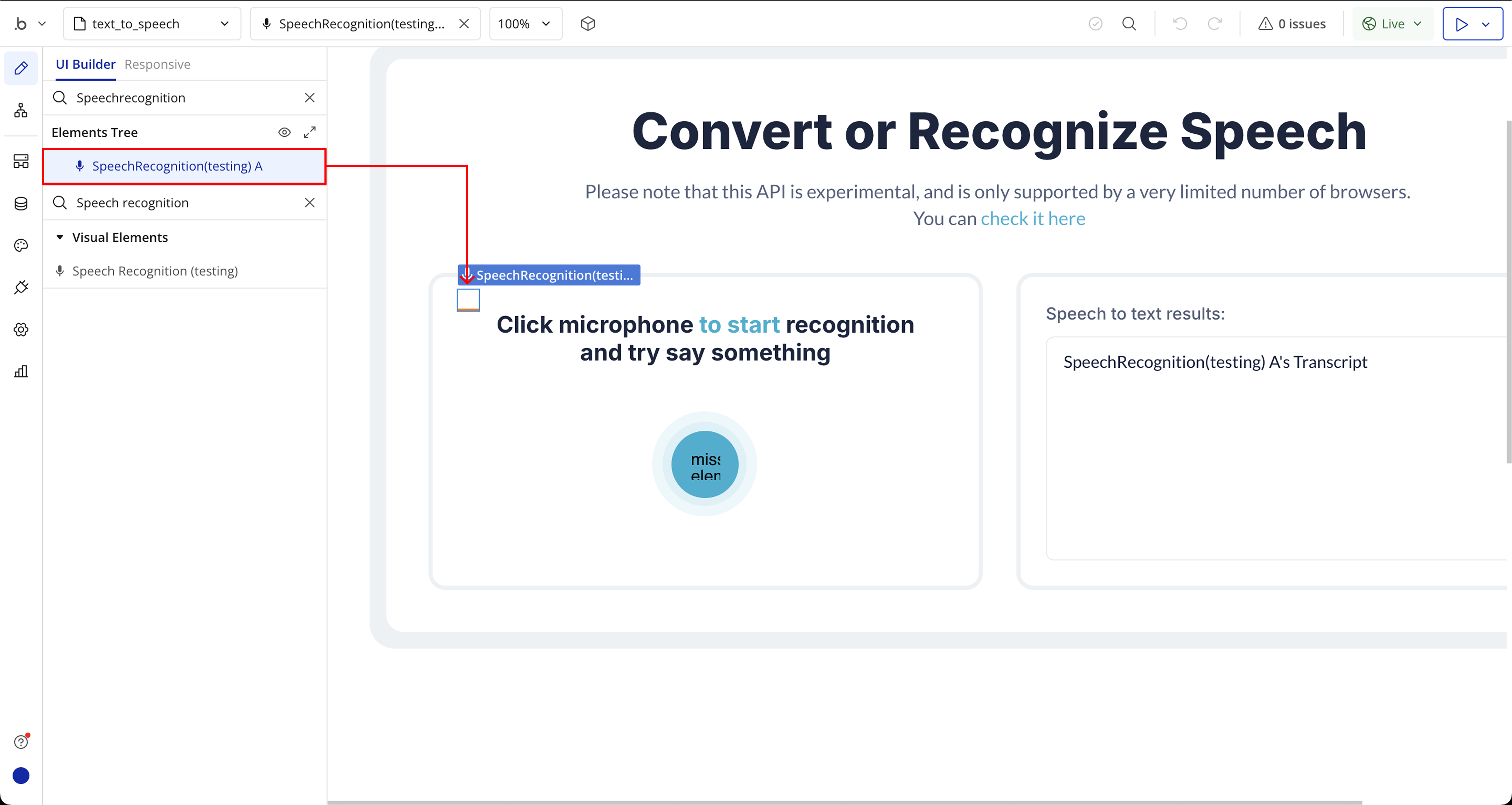
Step 3: Place the Element (Speech Recognition)
Step 4: Text to Speech Required Page Elements
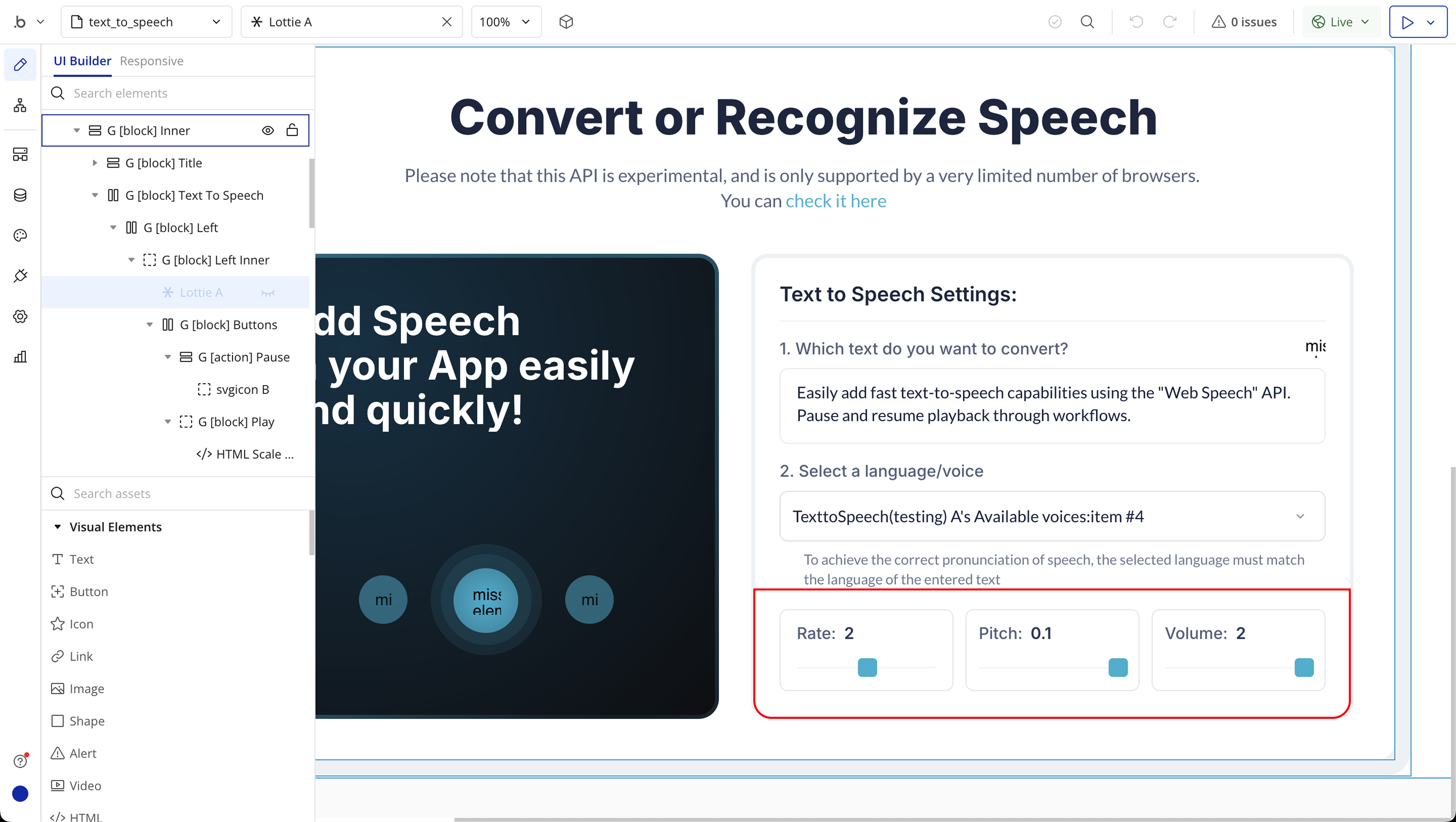
Step 5: Text to Speech Workflow Setup
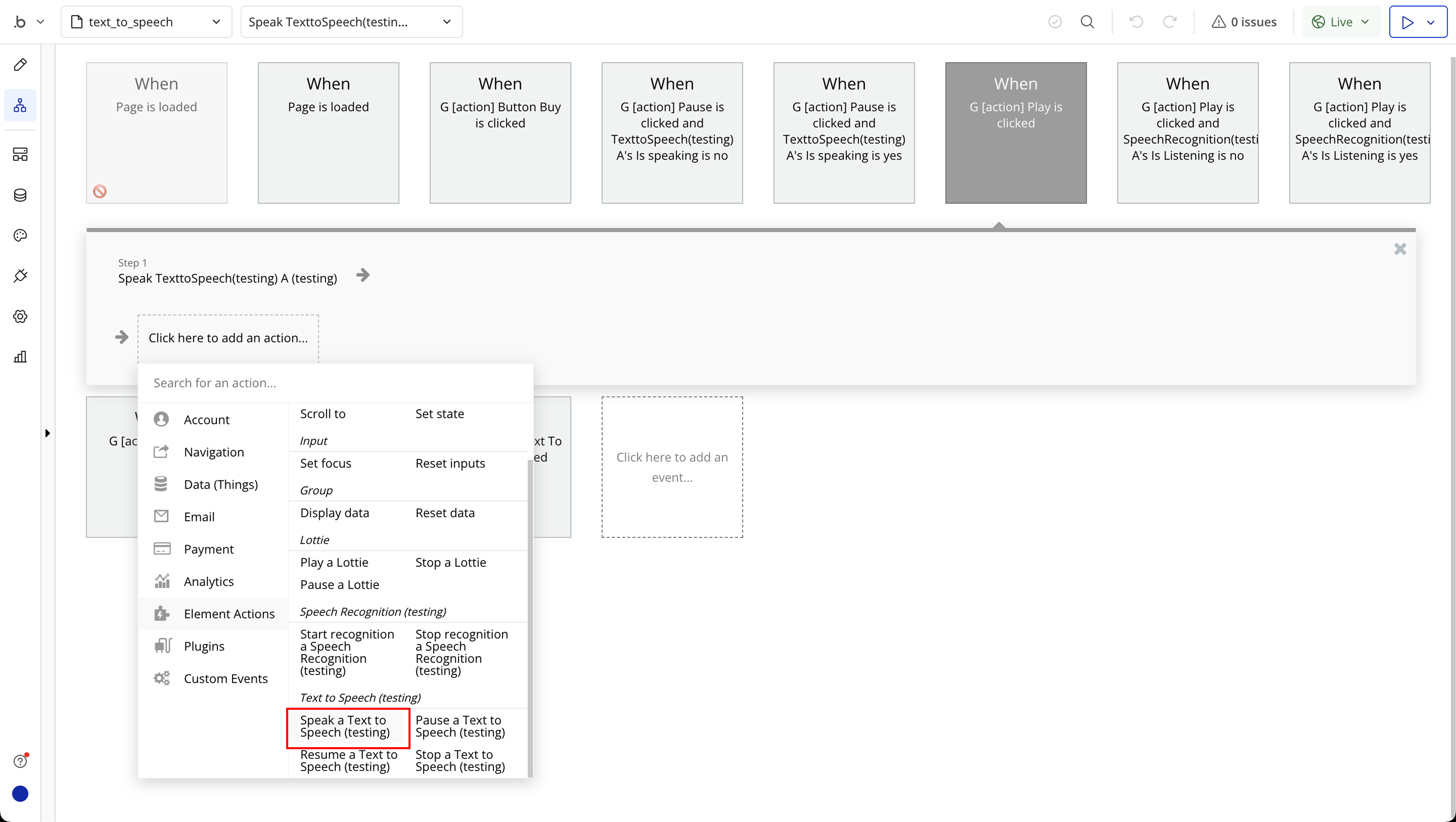
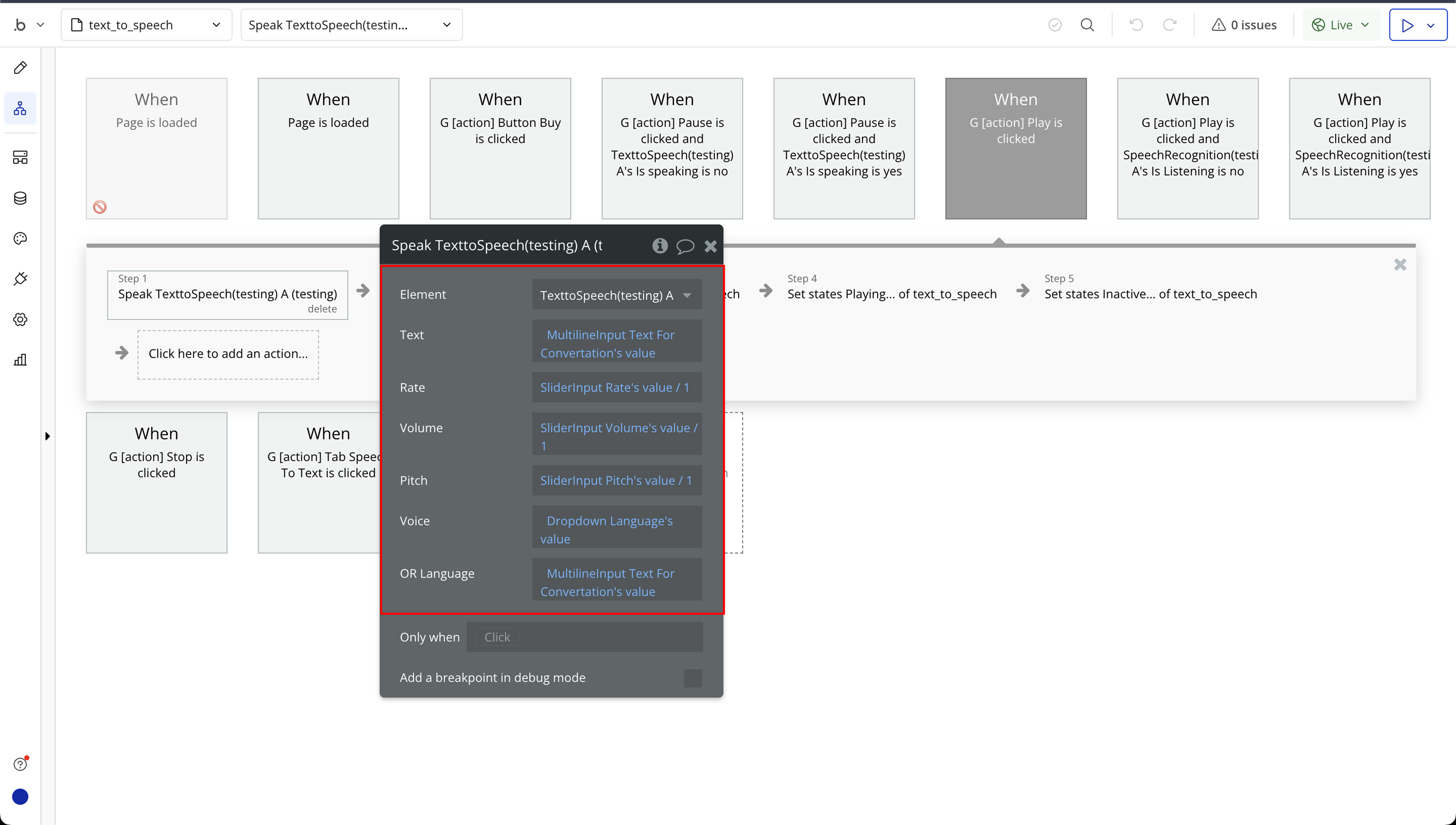
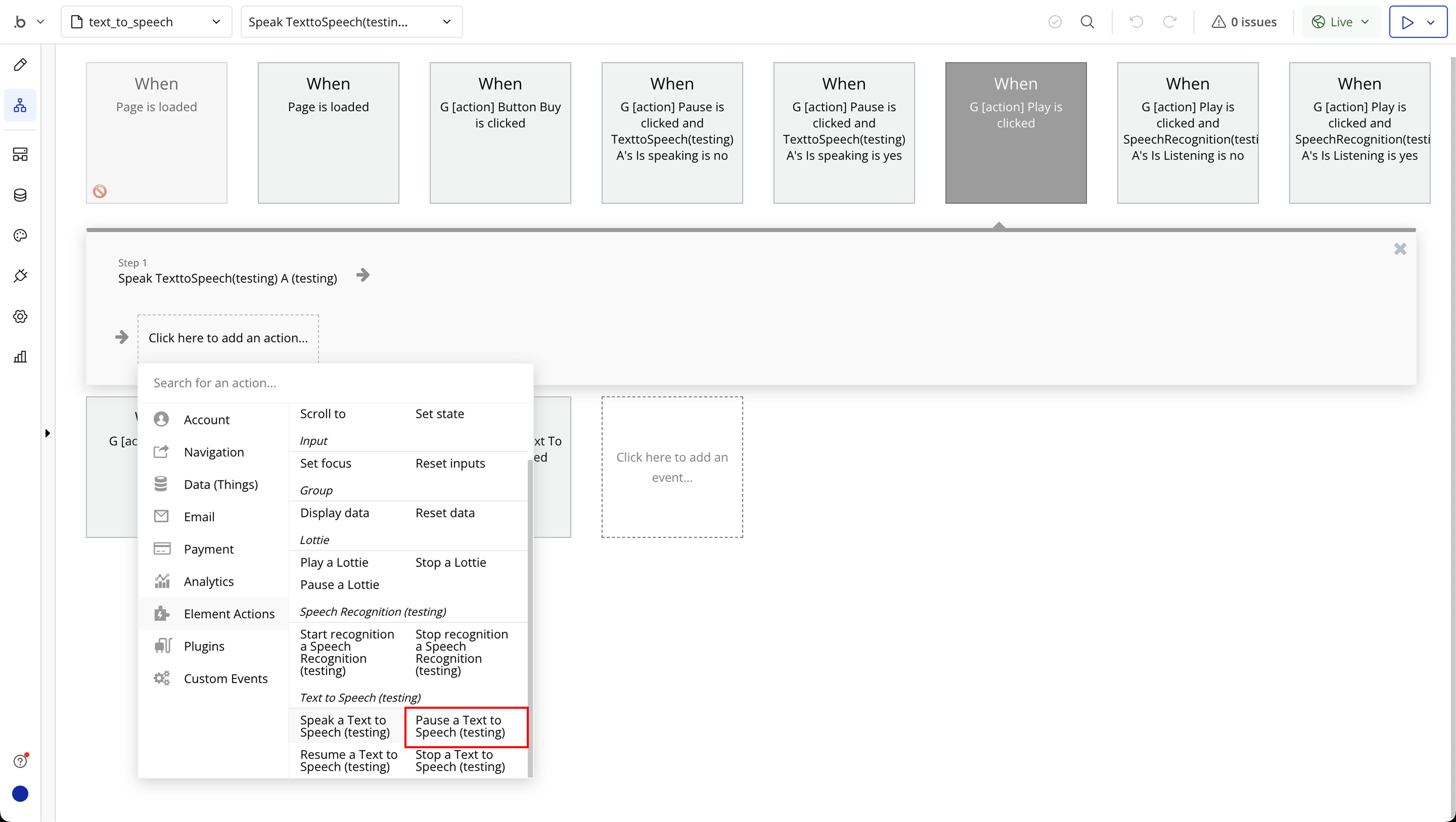
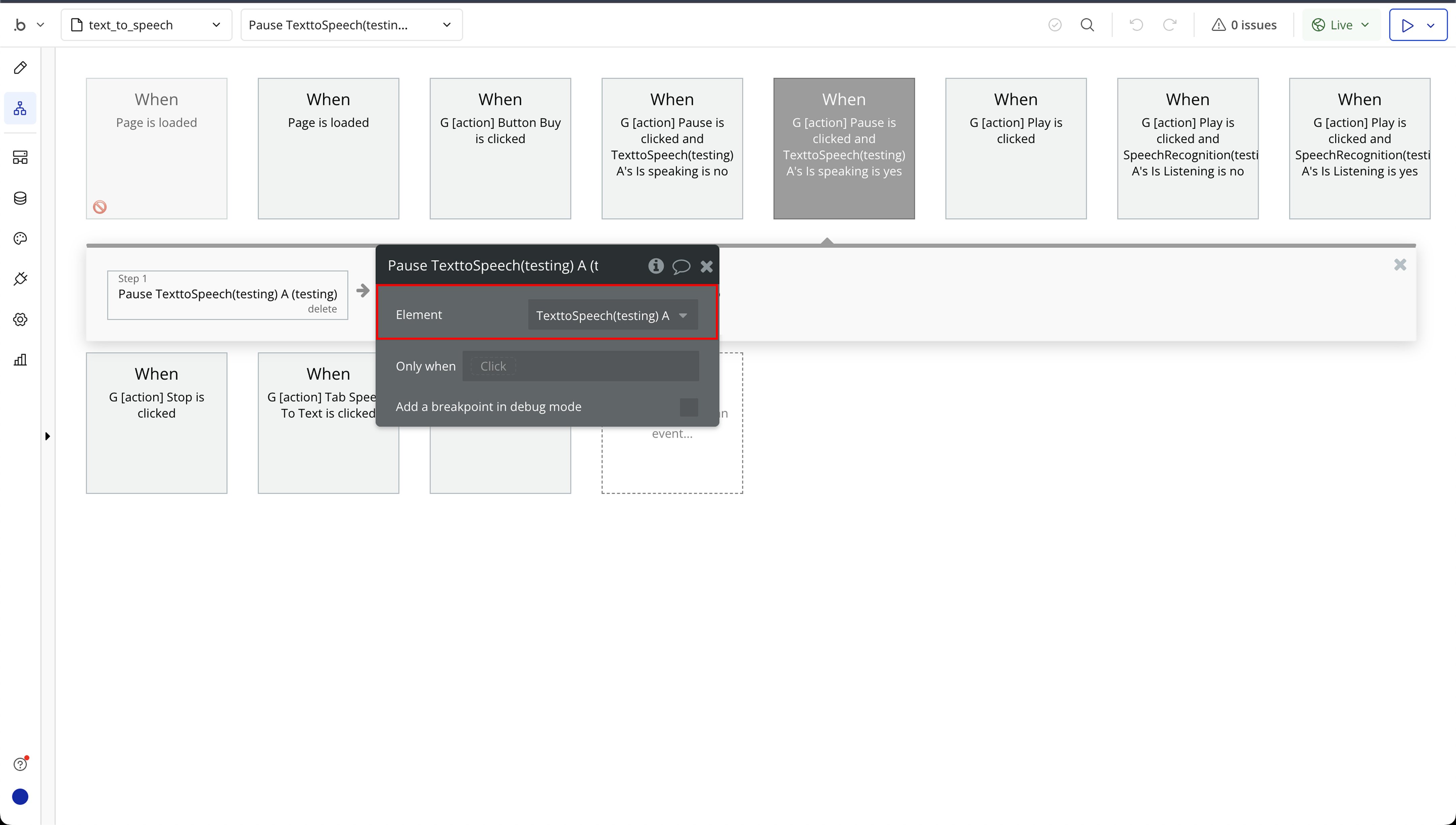
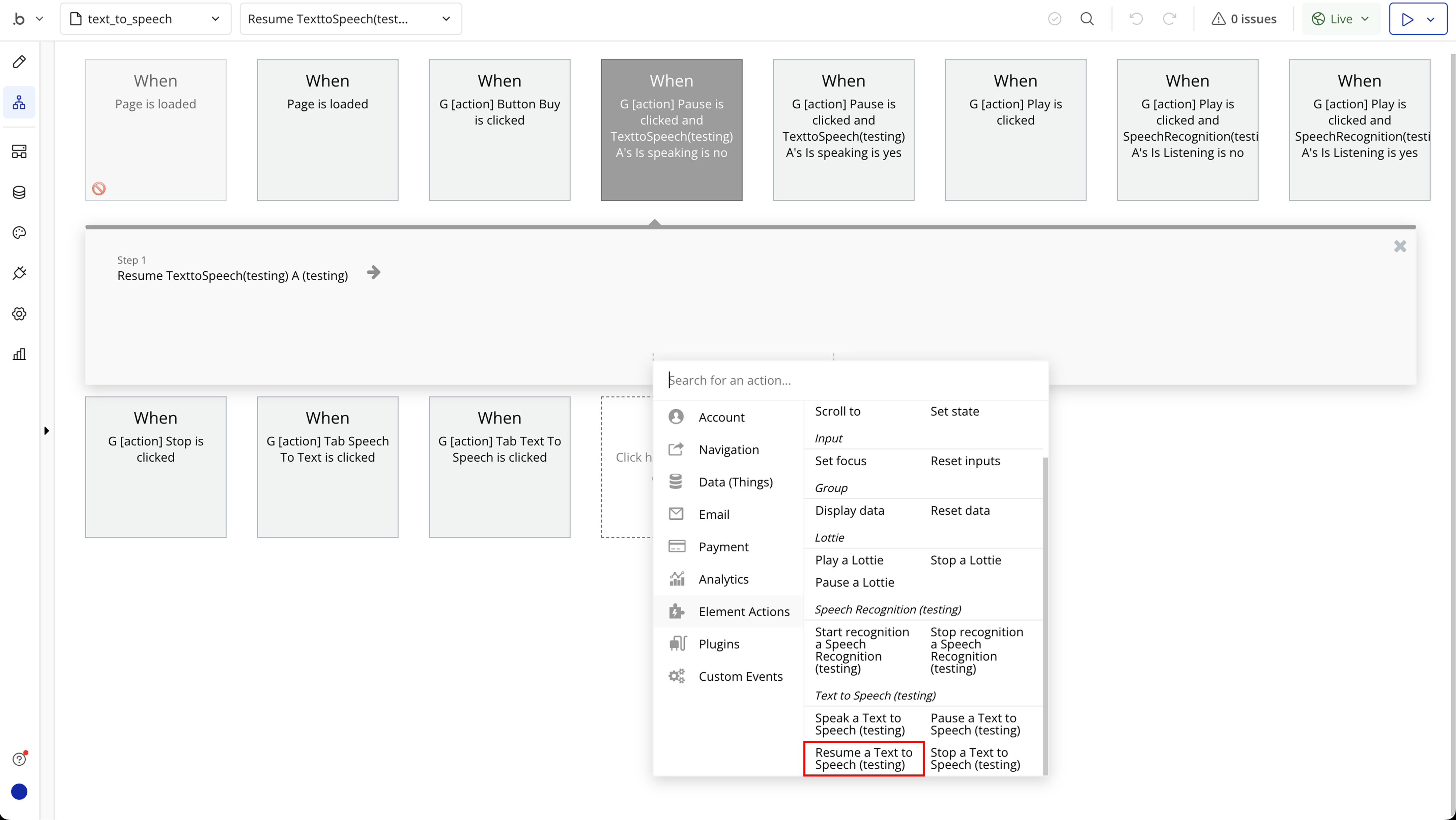
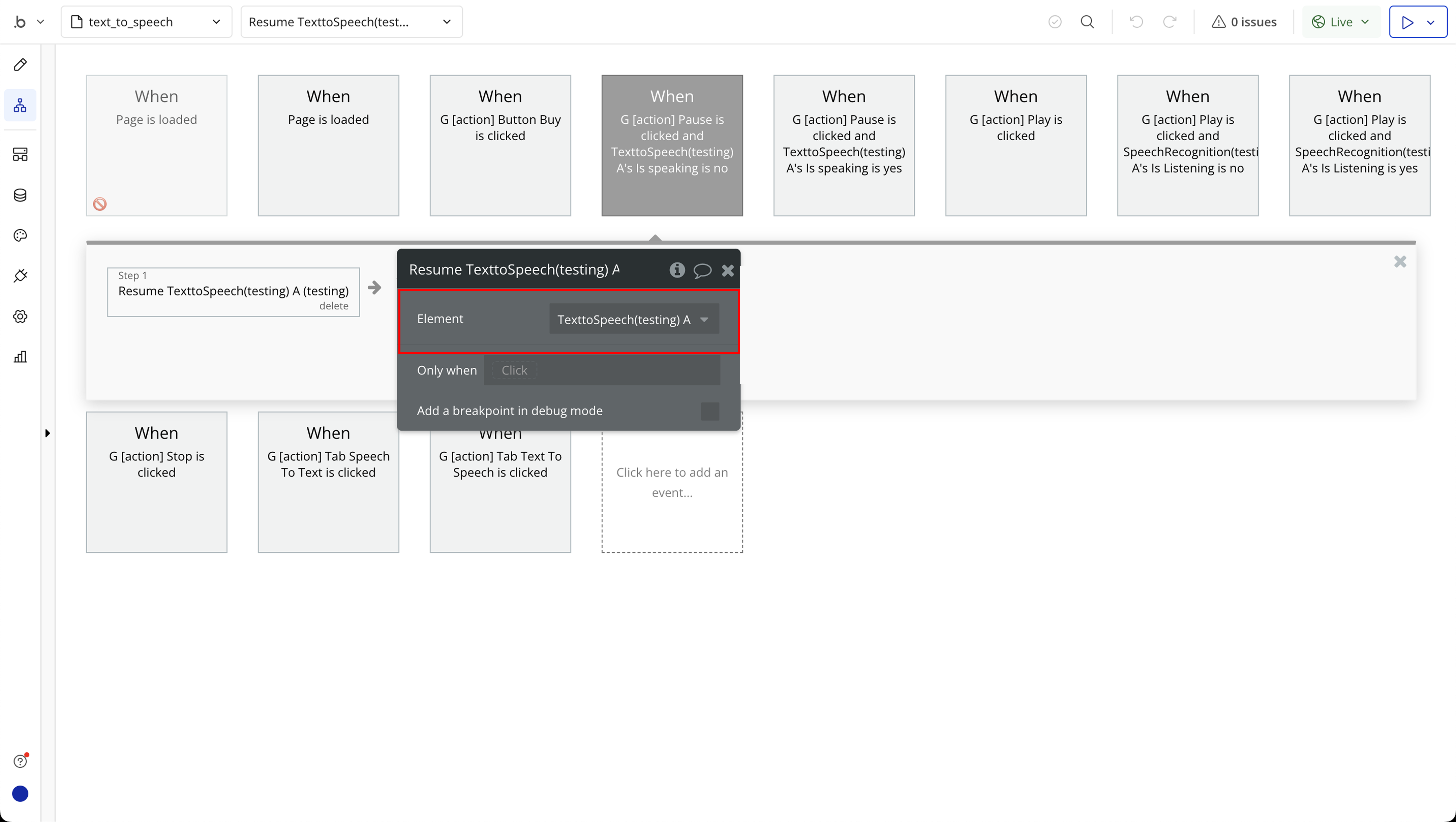
Step 6: Text to Speech Required Page Elements
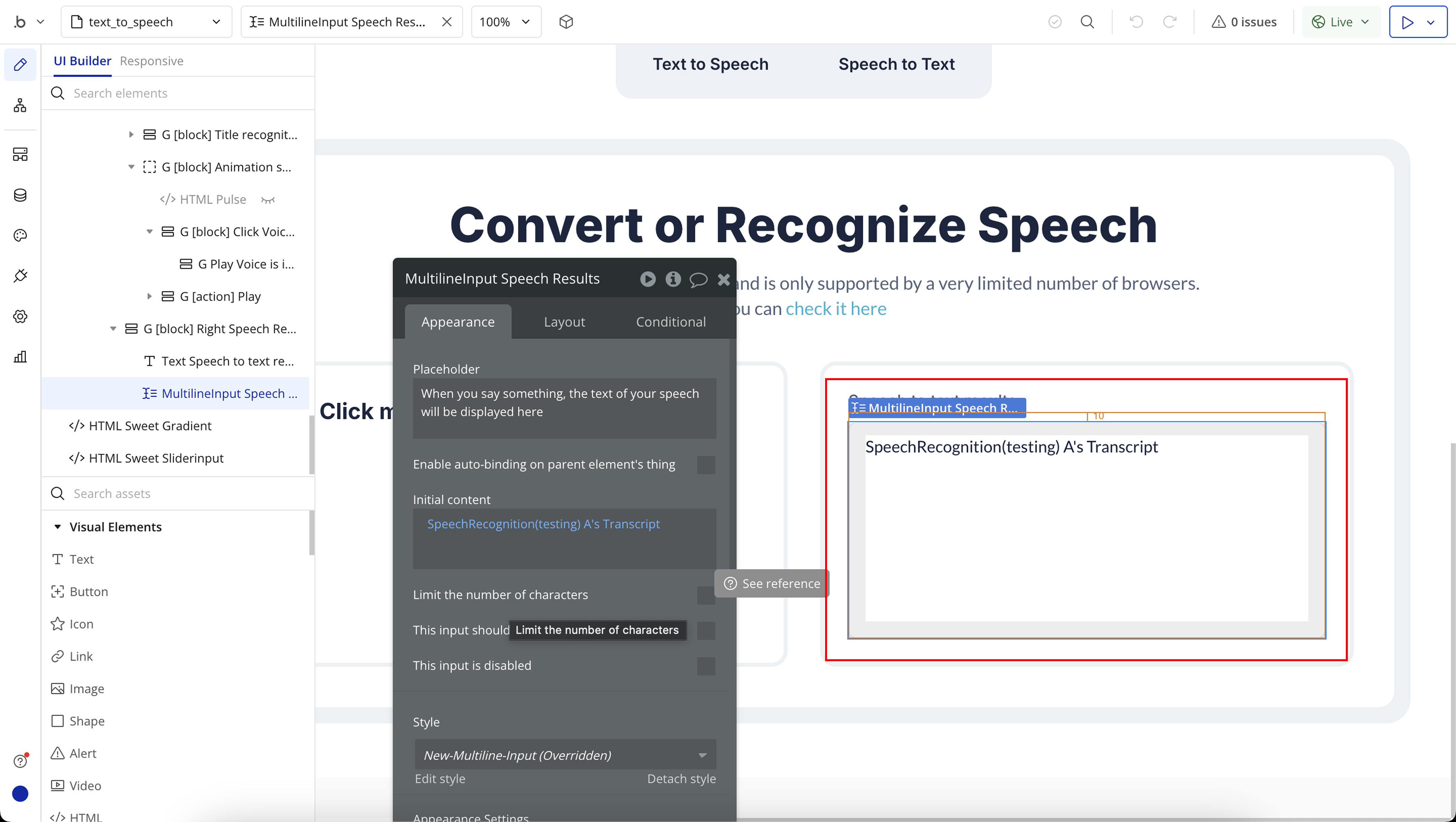
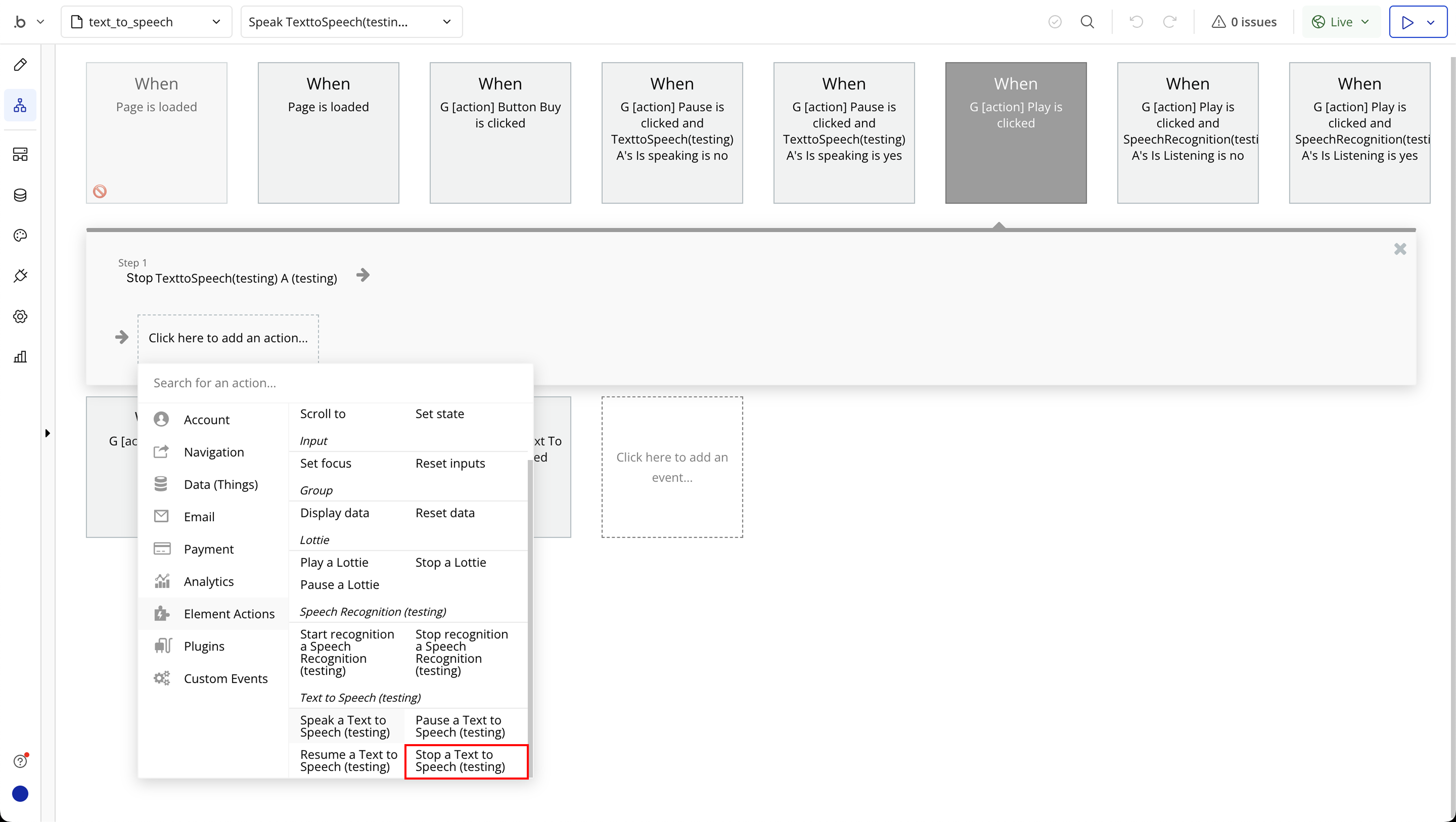
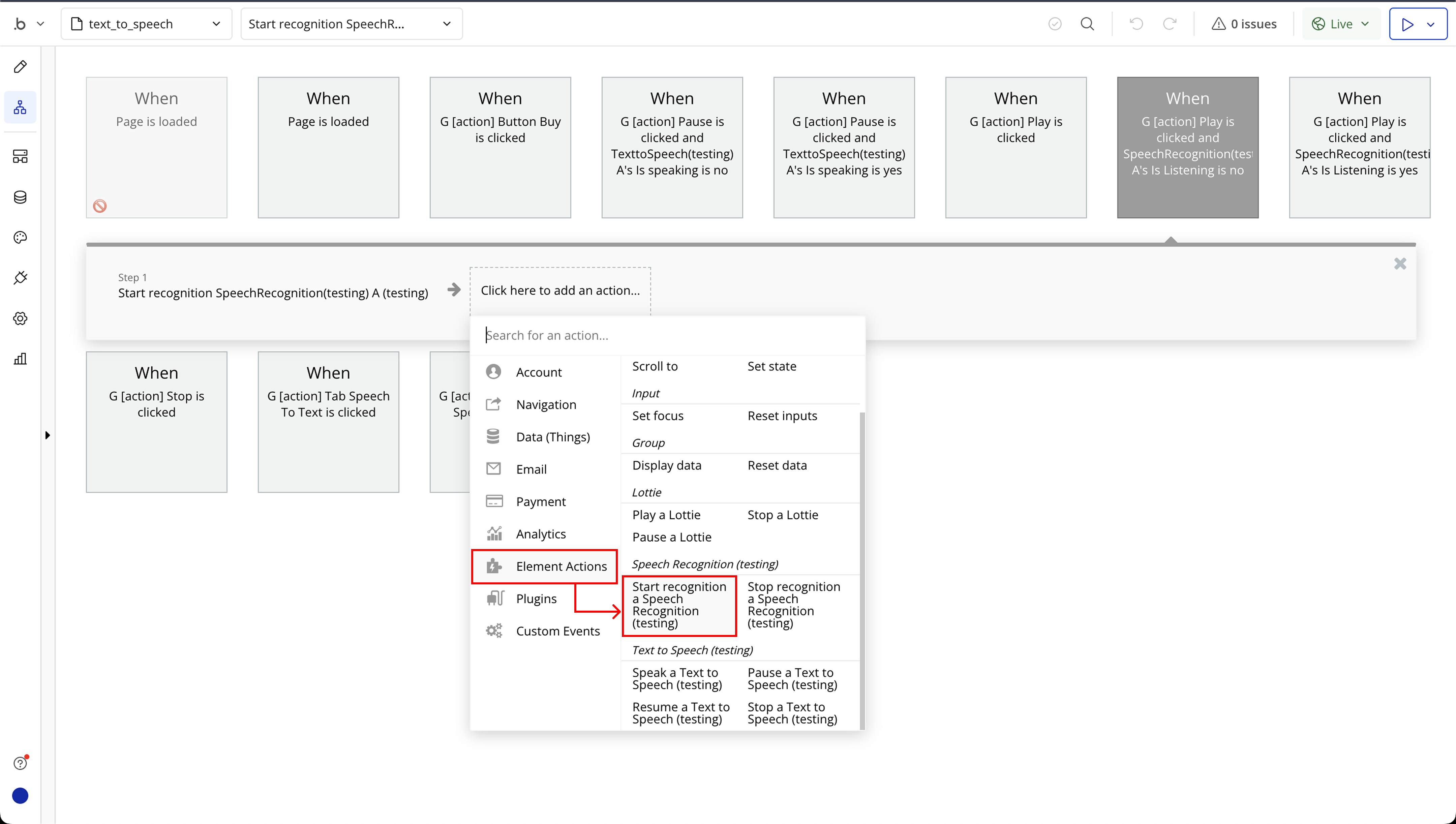
Step 7: Speech to Text Workflow Setup
Plugin Element Properties
Text to Speech
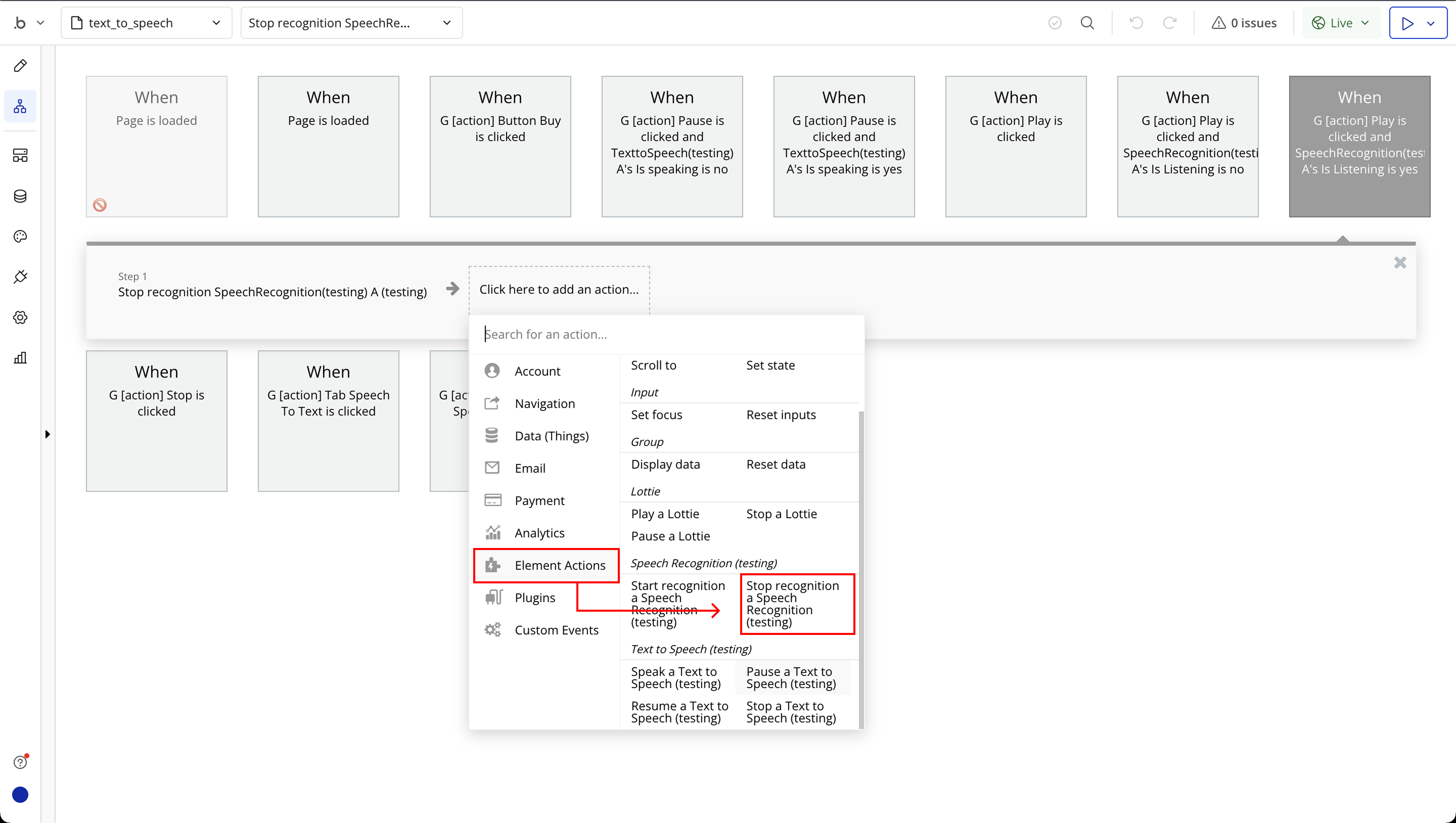
Element Actions
- Speak - Speak text (add to queue).
Title | Description | Type |
Text | The message you want the speech engine to say aloud. This should be plain text, such as a sentence or paragraph. | Text |
Rate | Controls the speed at which the text is spoken. The default is 1.0. Lower values (e.g. 0.5) make the speech slower, and higher values (e.g. 2.0) make it faster. | Number |
Volume | Sets the loudness of the speech output. Accepts values from 0.0 (muted) to 1.0 (full volume). The default is 1.0. | Number |
Pitch | Adjusts the pitch (tone) of the voice. The default is 1.0. Values below 1.0 result in a deeper voice, and values above 1.0 produce a higher-pitched voice. Range is usually from 0.0 to 2.0. | Number |
Voice | The specific voice to use for speech synthesis (e.g. "Google UK English Male"). Leave blank to use the browser’s default voice. Voice options vary by device and browser. | Text (optional) |
OR Language | Set the language locale (e.g., "en-US", "fr-FR") to influence which voice is chosen. This can help match the voice with the appropriate language accent if you’re not specifying a custom voice. | Text (optional) |
- Pause - Pause speaking.
- Resume - Resume speaking.
- Stop - Stop speaking and clear queue.
Exposed states
Title | Description | Type |
Available voices | List of all voices available on the current device | Text |
Speech synthesis supported | Returns yes if speech synthesis API is supported on current device | Checkbox (yes/no) |
Is speaking | Returns yes if text is currently being spoken | Checkbox (yes/no) |
Is paused | Returns yes if text is queued but currently paused | Checkbox (yes/no) |
Default voice | The current device’s default voice | Text |
Available languages | List of the languages of all voices available on the current device | Text |
Is Local Service | List of whether each voice is a local service (or remote) | Checkbox (yes/no) |
Speech Recognition
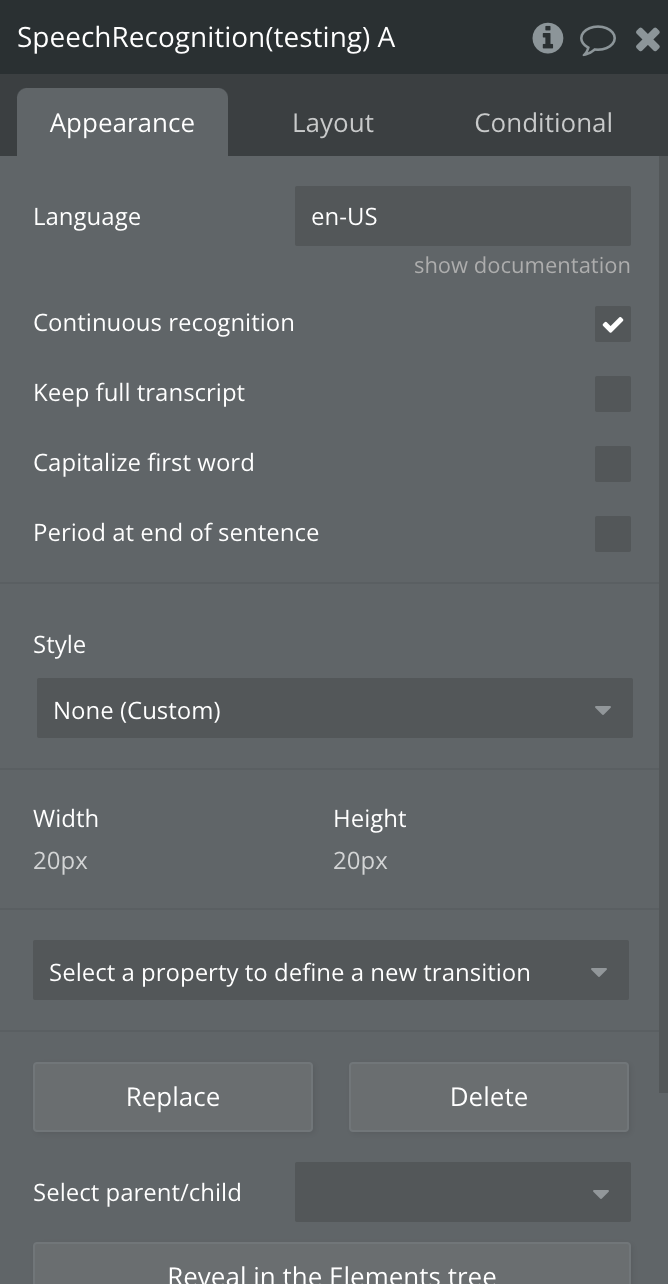
Fields:
Title | Description | Type |
Language | Language code for the speech you want to recognize (e.g. "en-US" for English - United States).
Note: There’s no guaranteed method to fetch all supported languages, but using the same language codes from the Text-to-Speech element is a reliable approach. | Text |
Continuous recognition | When checked, the speech recognition continues listening until manually stopped, allowing longer or ongoing speech input.
If unchecked, it will stop automatically after detecting a pause. | Checkbox (yes/no) |
Keep full transcript | When enabled, the plugin will keep building a full transcript of everything heard in one session.
If disabled, only the latest phrase will be available. | Checkbox (yes/no) |
Capitalize first word | Automatically capitalizes the first word of each new result, helpful for formatting transcripts more naturally. | Checkbox (yes/no) |
Period at end of sentence | Appends a period (.) at the end of each recognized sentence or phrase, useful for auto-punctuation in generated transcripts. | Checkbox (yes/no) |
Element Actions
- Start recognition - Begins listening for the user’s speech input and starts transcribing it into text based on the selected configuration (language, continuous mode, etc.). This action uses the browser's speech recognition engine to capture audio in real time.
- Stop recognition - Stops the speech recognition process manually. This action ends the current transcription session and prevents further audio input from being processed.
Exposed states
Title | Description | Type |
Transcript | Returns the full or partial transcribed text captured during the speech recognition session. This text updates in real time as the user speaks. | Text |
Is Listening | Indicates whether the plugin is currently active and listening for speech input. Useful for toggling UI elements or controlling flow logic. | Checkbox (yes/no) |
Sound Happening | Shows whether sound (not necessarily speech) is currently being detected. Can be used to visualize audio activity (like mic input waves) or signal that the user is speaking. | Checkbox (yes/no) |
Speech Recognition Supported | Checks if the current browser supports the Web Speech Recognition API. If this is no, the feature won’t work and a fallback should be considered. | Checkbox (yes/no) |
Element Events
Title | Description |
Speech Recognized | This event is triggered each time speech is successfully recognized and converted into text. You can use this to run workflows based on the transcribed content, such as storing the text, triggering search, or interacting with other elements in your app. |