Uberduck Text-To-Voice AI is the perfect plugin for transforming text into well-recorded, natural voices. You can easily create your own voices and transform text into spoken words that sound just like the person you want them to. You can use Uberduck to produce audio for your website and applications, or to provide better customer service for your customers.
Prerequisites
First of all you have to get API key from Uberduck and then you can use the Uberduck Text-To-Voice AI.
How to setup
The first thing you will need to do is sign up for an Uberduck account! Go to the signup page and create an account.
Create an API key and write down the secret key in a secret place. You can create as many API keys as you'd like, but can only view the secret key when you create it.
Paste your Key as the Username and your Secret Key as your Password in plugin settings of your app
You'll now be able to access the API. For unlimited access and access to commercial use voices, purchase a plan at Uberduck pricing page.
Plugin Data/Action Calls (API Calls only)
Action Calls:
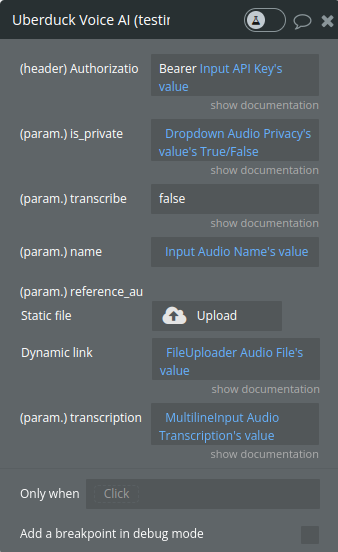
Add Reference Audio (Legacy)
Allows users to submit reference audio to the Uberduck system. The reference audio can be used for various purposes, such as improving speech synthesis quality or training custom voice models.
Name
Description
Type
is_private
A flag to indicate whether the reference audio should be kept private. The default value is false, meaning the audio is not private.
boolean
default: false
transcribe
A flag to indicate whether the system should automatically transcribe the audio. The default is false.
boolean
default: false
name
The name or label for the reference audio. This helps in identifying and organizing the audio within the system.
string
reference_audio
The audio file that you want to upload as reference audio. The format and size specifications for the file should be adhered to as per Uberduck API guidelines.
file, required
transcription
The textual transcription of the audio content. This transcription should accurately represent the spoken content in the audio file.
string
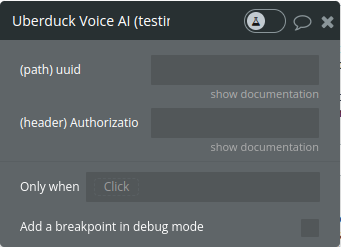
Get text-to-speech request status(Legacy)
This API endpoint is used to retrieve the status of a text-to-speech request previously submitted to the Uberduck API. It is useful for tracking the progress and completion of a speech synthesis operation.
Name
Description
Type
uuid
The unique identifier for the text-to-speech request. This UUID is provided when you initially make a speech request and is used to track the specific request.
string(required)
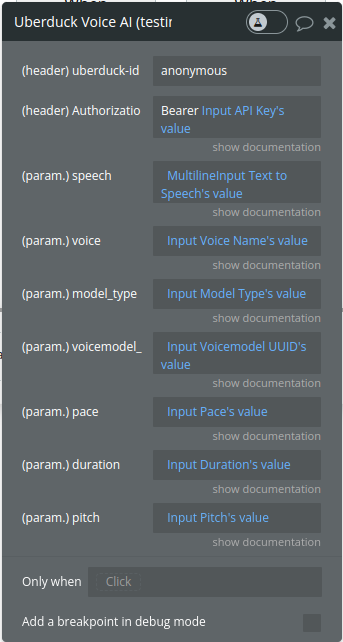
Generate Speech (Legacy)
This API endpoint is used to synthesize speech asynchronously. It allows users to convert text into spoken words using a range of different voices. The voice can be specified using voice and model_type parameters, or by providing a voicemodel_uuid. Note that not all voices support pace, duration, and pitch controls; these are available only for a subset of voices.
Name
Description
Type
speech
The text to be converted into speech.
string(required)
voice
Specifies the voice to be used
string(optional)
model_type
The type of voice model to be used.
string(optional)
voicemodel_uuid
A unique identifier for a specific voice model.
string(optional)
pace
Controls the pace of the speech. The default value is 1.
number(optional)
duration
An array that specifies the duration of the speech.
array of numbers, optional
pitch
An array that specifies the pitch of the speech.
array of numbers, optional
Generate Speech Synchronously
Voice Specification:
The voice for the speech synthesis can be specified in two ways:
voice + model_type: Specify the voice and the type of voice model to be used.
voicemodel_uuid: Use a unique identifier for a specific voice model.
Supported Controls:
Pace, duration, and pitch: These controls are available only for a select subset of voices that support these features.
To check if a given voice supports these controls, query /voice-data or /voices/<voicemodel-uuid>/detail and review the controls boolean in the response.
For fields description please see Generate Speech action above
This API endpoint is designed to synthesize speech synchronously, returning the output as binary 16-bit WAV data with a sample rate of 22050 Hz. This method is suitable for applications that require immediate audio feedback. It supports various voice options, and for some voices, additional controls like pace, duration, and pitch are available.
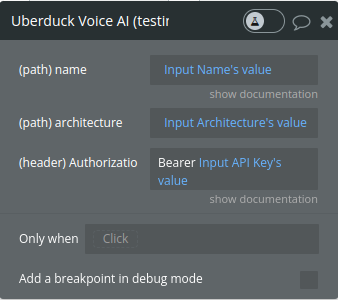
Get Voice by Architecture (Legacy)
Focuses on retrieving information about voice models based on their architecture. It allows users to filter and understand different voice models within the Uberduck system based on their underlying architecture.
Name
Description
Type
name
The name of the voice about which information is sought. This parameter is essential to identify the specific voice in the Uberduck voice library.
string(required)
architecture
Specifies the architecture of the voice model. This parameter can be used to filter the information for a specific type of voice model architecture.
string(optional)
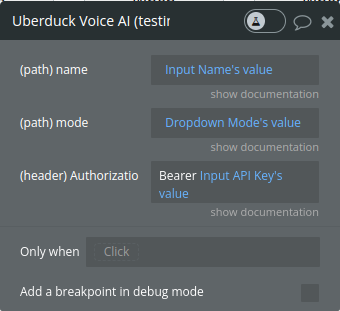
Get Voice
Retrieves information about voice models based on their mode. It is particularly useful for users interested in exploring voice models according to their operational or functional modes within the Uberduck system.
Name
Description
Type
name
The name of the voice about which information is sought. This parameter is essential to identify the specific voice in the Uberduck voice library.
string(required)
mode
Indicates the mode of the voice model. This could refer to different operational or functional modes available for the voice model.
string(optional)
Model Selection
This API endpoint retrieves the list of available voice models from the Uberduck system. It allows users to explore supported architectures and models that can be used for text-to-speech generation.
Response:
Field
Description
Type
uuid
Unique identifier of the voice model
string
name
Model display name
string
architecture
The architecture type of the model (e.g., tacotron2, gpt, etc.)
string
description
Short description of the model
string
controls
Indicates whether pace, pitch, and duration controls are supported
boolean
language
Language supported by the model
string
sample_rate
Audio sample rate
number
Data calls:
List Reference Audios (Legacy)
List all the reference audio files associated with a user's account on the Uberduck platform. It is an efficient way to retrieve a catalog of previously submitted or used reference audio files, facilitating easy access and management.
Response:
The response will consist of a list of reference audio files. Each entry in the list typically includes details like the name of the audio file, the date it was uploaded, its duration, and any other relevant metadata.
Voice Detail
Used to retrieve detailed information about a specific voice model identified by its unique UUID in the Uberduck system. It provides comprehensive data about the voice model's characteristics, capabilities, and any other relevant attributes.
Name
Description
Type
uuid
The unique identifier for the voice model. This UUID is essential to specify which voice model's details are being requested.
string(required)
Fetch Voice Samples
Return sample outputs from a specified VoiceModel. It's a useful resource for users who want to preview the capabilities and quality of a particular voice model by listening to its sample audio outputs.
Name
Description
Type
uuid
The unique identifier for the voice model whose samples are being requested. This UUID is crucial for specifying which voice model's samples are to be listed.
string(required)
Get Voice Stats(Legacy)
Allows users to obtain usage and quality statistics for specific voices available on the Uberduck platform. It's designed to provide insights into how different voice models are being used and their performance metrics.
Name
Description
Type
username
The username associated with the voice models whose statistics are being queried. This parameter is used to filter the statistics to only those voices linked to the specified user account.
string(optional)
voicemodel uuid
An array of unique identifiers for specific voice models. By providing one or more UUIDs, users can obtain statistics for these particular voice models. This is useful for analyzing the performance and usage of specific voices.
array of strings(optional)
Response:
The response from this API call will include statistical data related to the usage and quality of the specified voice models. This may encompass metrics such as the number of times a voice model has been used, the quality ratings it has received, and other relevant performance indicators.
Convert English to ARPAbet
Designed to convert English text into ARPAbet, a phonetic transcription code used primarily in speech processing. ARPAbet is often utilized in text-to-speech and speech recognition systems to represent how words are pronounced.
Name
Description
Type
text
The English text that needs to be converted to ARPAbet. This text is the input for which the API will provide a phonetic representation.
string(required)
Response:
The response from this API call will be the ARPAbet phonetic transcription of the provided English text. It translates the standard English spelling into its corresponding phonetic sounds as per the ARPAbet conventions.