Link to plugin page: https://zeroqode.com/plugin/1689633204183x212637344857662180
Demo to preview the settings
Introduction
With OpenAI & chatGPT, you gain access to various functionalities:
- Get a list of available OpenAI models.
- Employ the moderation endpoint as a tool to verify content compliance with OpenAI's content policy. More details can be found at: Moderation API Reference
- Edit text by providing a prompt and an instruction, and the model will return an edited version of the prompt. For more information, visit: Edit Text API Reference
- Generate images using prompts and/or input images, with the model producing new images. Check out: Generate Images API Reference
- Employ the Generate Completion feature for a multitude of tasks, such as answering questions based on existing knowledge, translating complex text into simpler concepts, converting text into programmatic commands, creating code to call the Stripe API, constructing tables from long-form text, determining the time complexity of a function, detecting sentiment from status updates, extracting keywords from text, writing ad copy for product descriptions, summarizing text with a 'tl;dr:', engaging in QA-style chatbot interactions, generating color descriptions from text, crafting short horror stories from topics, engaging in open-ended conversations with an AI assistant, creating interview questions, generating restaurant reviews from a few words, simulating text message conversations, extracting contact information from text, creating product names based on examples, classifying items into categories via examples, translating English text into French, Spanish, and Japanese, and correcting sentences into standard English. Additionally, you can use it to compose Email responses.
Prerequisites
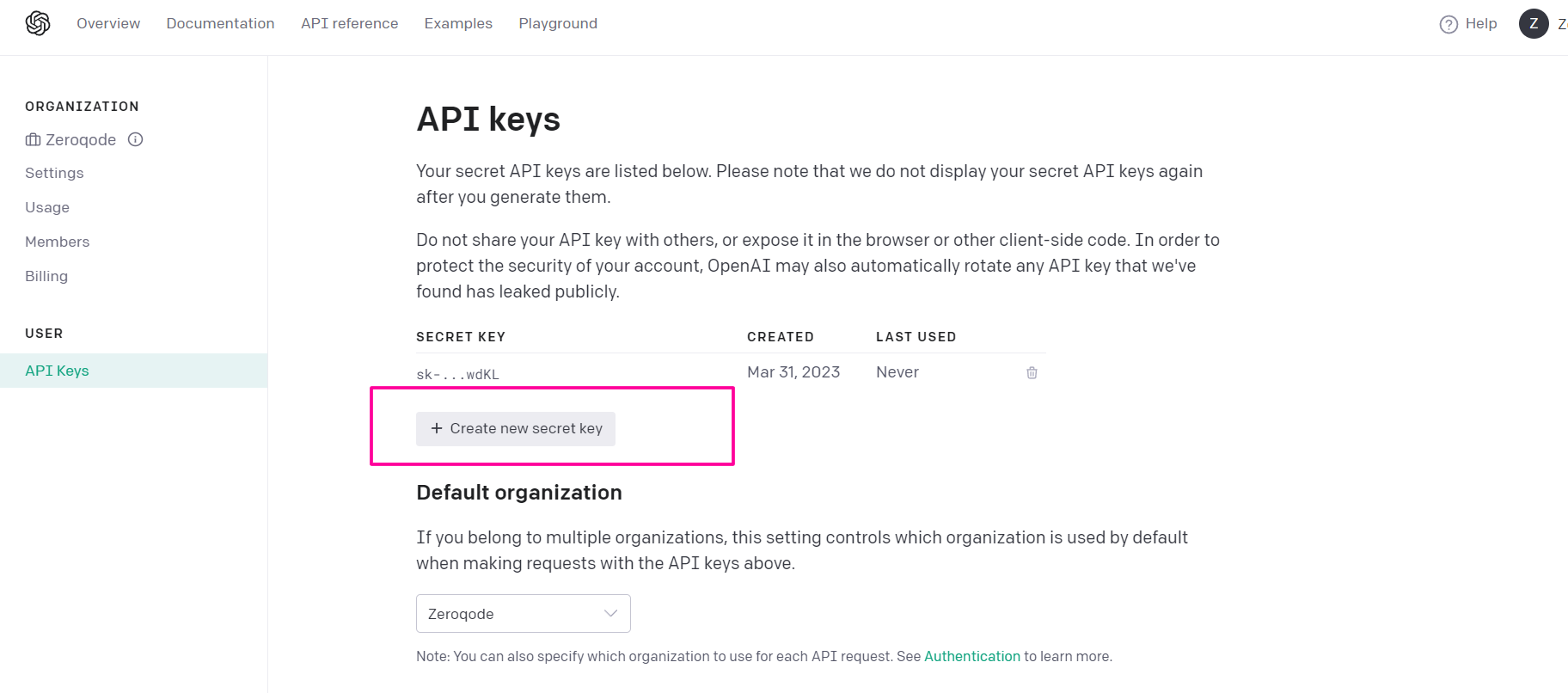
To use this plugin, you need to register on the OpenAI dashboard and insert your keys into the plugin
How to Setup
- Create an account: https://platform.openai.com/
- Create an API keys: https://platform.openai.com/account/api-keys
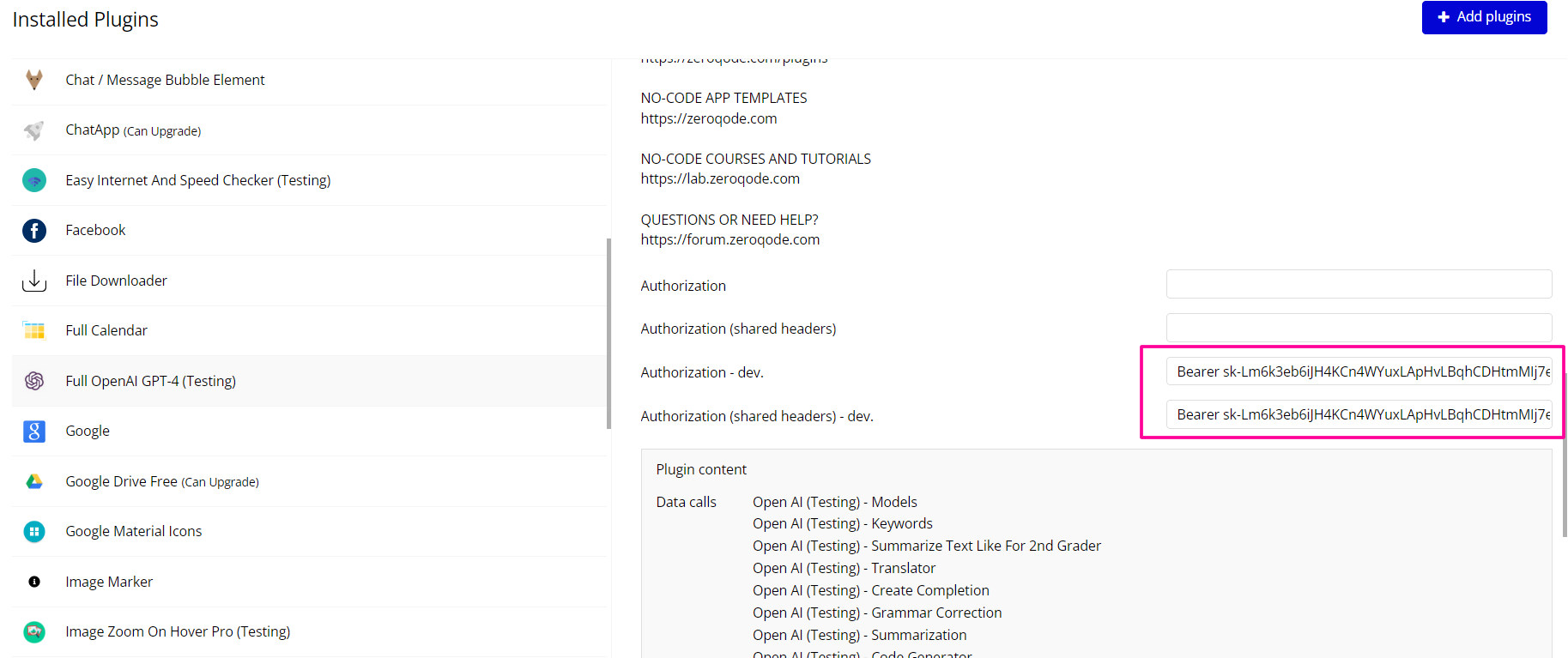
- Copy the key and set it to in the plugin settings with the word key “Bearer”
Plugin Data/Action Calls
1. Generate Completion - generating a response or output using GPT-3.5 Turbo, which is a version of OpenAI's powerful language model, GPT-3. When you provide input or prompt to GPT-3.5, it processes the information and generates a completion, which is the model's coherent and contextually relevant response to the given input. This completion can be a piece of text, an answer to a question, or any other form of written output that the model generates based on the input provided.
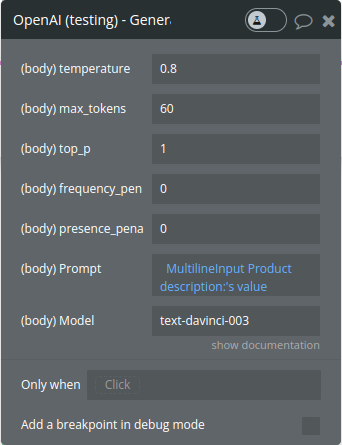
Param Name | Description | Type |
Temperature | What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic. | Number
Defaults to 1 |
Max_tokens | The maximum number of tokens to generate in the completion.
The token count of your prompt plus max_tokens cannot exceed the model's context length. Most models have a context length of 2048 tokens (except for the newest models, which support 4096). | Integer
Defaults to 16 |
Top_p | An alternative to sampling with temperature is called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered. | Number
Optional
Defaults to 1 |
Frequency_penalty | Number between -2.0 and 2.0. Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the model's likelihood to repeat the same line verbatim. | Number
Defaults to 0 |
Presence_penalty | Number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model's likelihood to talk about new topics. | Number
Optional
Defaults to 0 |
Prompt | It is the text that, you give for processing | Text |
Model | Model name ex. text-davinci-003 | text/Optional |
- Generate Image - The image generations endpoint allows you to create an original image given a text prompt. Generated images can have a size of 256x256, 512x512, or 1024x1024 pixels. Smaller sizes are faster to generate. You can request 1-10 images at a time using the number parameter.
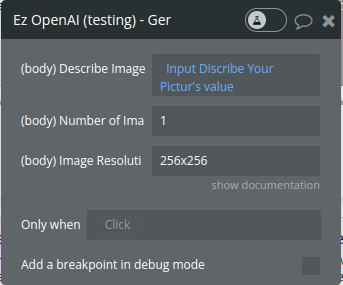
Param Name | Description | Type |
Describe image | A text description of the desired image(s). The maximum length is 1000 characters | Text |
Number of Images | The number of images to generate. Must be between 1 and 10. | Integer
Optional
Defaults to 1 |
Image Resolution | The size of the generated images. Must be one of 256x256, 512x512, or 1024x1024. | Text
Optional
Defaults to 1024x1024 |
- Get Models - lists the currently available models, and provides basic information about each one such as the owner and availability.
Returns a list of model objects.
- Edit Text
Correct a sentence or a text if it needs grammatical corrections
This action is based on GPT-3.5 module
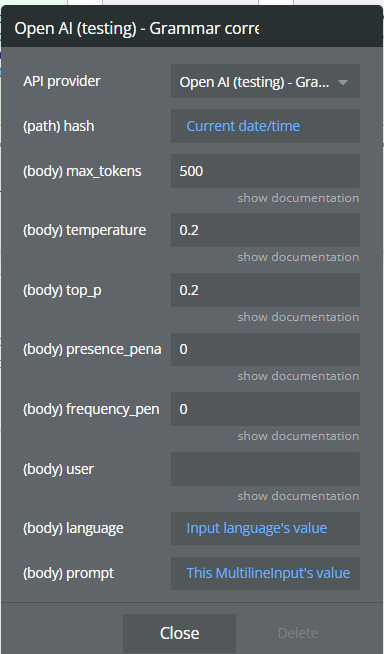
Description | Type | |
Hash | hash is a field that receives a dynamic value, for example, the current time, to ensure that the calls are always updated | Text |
Max_tokens | The maximum number of tokens to generate in the completion.
The token count of your prompt plus max_tokens cannot exceed the model's context length. Most models have a context length of 2048 tokens (except for the newest models, which support 4096). | Integer
Defaults to 16 |
Temperature | What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic. | Number
Defaults to 1 |
Top_p | An alternative to sampling with temperature, is called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered. | Number
Defaults to 1 |
Presence_penalty | Number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model's likelihood to talk about new topics. | Number
Defaults to 0 |
Frequency_penalty | Number between -2.0 and 2.0. Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the model's likelihood to repeat the same line verbatim. | Number
Defaults to 0 |
Prompt | It is the text that, you give for processing | Text |
user | A unique identifier representing your end-user, which can help OpenAI to monitor and detect abuse | Text
Optional |
Language | The language in which the text is written. | Text |
- Moderation Text - Classifies if text violates OpenAI's Content Policy
Param Name | Description | Type |
Input | The input text to classify | Text |
Returns a moderation object
6. Get the list of assistants (Beta).
7. Delete assistants (Beta).
Param Name | Description | Type |
assistant_id | The ID of the assistant to modify | Text |
7. Retrieve assistant (Beta).
Param Name | Description | Type |
assistant_id | The ID of the assistant to modify | Text |
8. Create thread (Beta).
Create threads that assistants can interact with.
9. Create messages (Beta).
Create messages within threads
Param Name | Description | Type |
thread_id | The thread ID that this message belongs to. | Text |
message | The content of the message in array of text and/or images. | Text |
10. Retrieve message (Beta).
Retrieve a message.
Param Name | Description | Type |
thread_id | The thread ID that this message belongs to. | Text |
message_id | The content of the message in array of text and/or images. | Text |
11. Retrieve messages list (Beta).
Returns a list of messages for a given thread.
Param Name | Description | Type |
thread_id | The thread ID that this message belongs to. | Text |
12. Create run (Beta).
Represents an execution run on a thread.
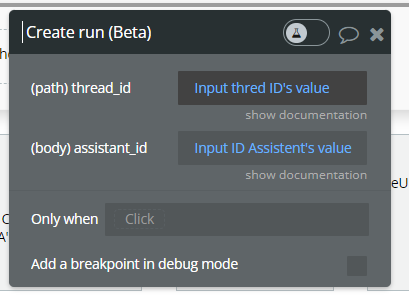
Param Name | Description | Type |
thread_id | The thread ID that this message belongs to. | Text |
assistant_id | The ID of the assistant used for execution of this run. | Text |
Workflow example
- Set an event to trigger a desired action, for example Generate Completion
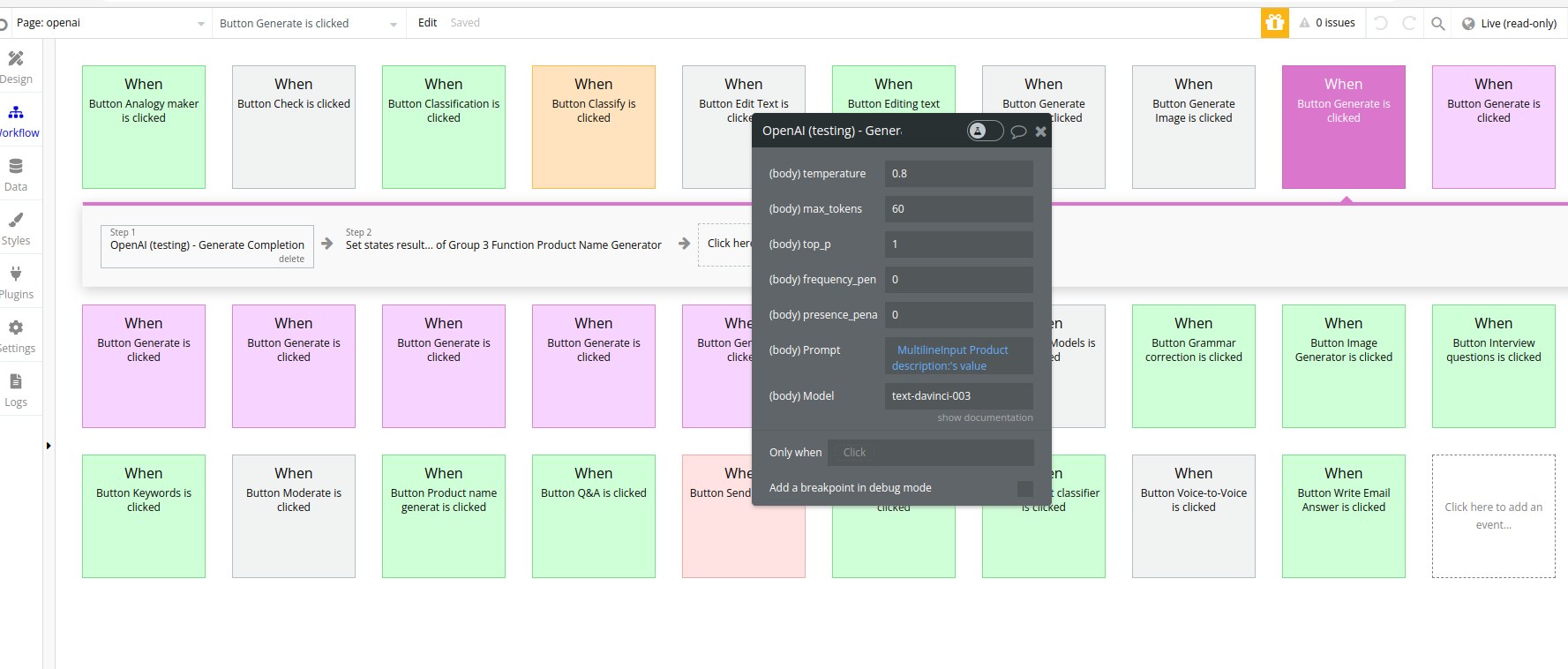
- Set a custom state and store the result of the action
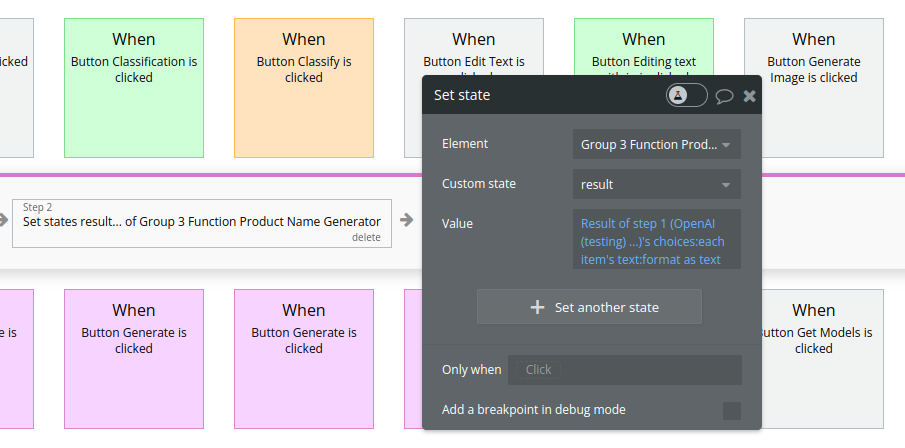
- Display the result stored in the custom stateA
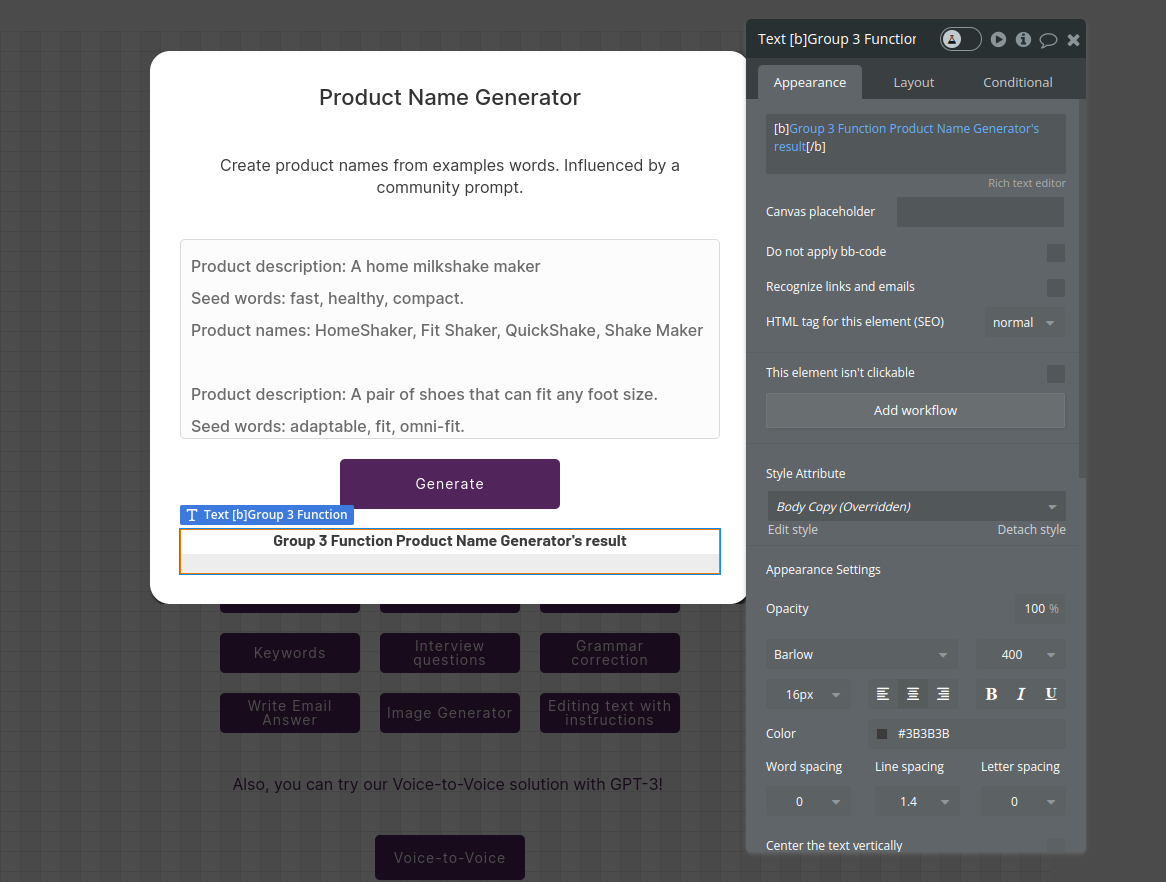
13. Create Vector Store
Vector stores are used to store files for use by the
file_search tool.
Name | Description | Type |
Name | The name of the vector store. | Text |
Return Values:
A vector store object.
14. Retrieve File
Returns information about a specific file.
Name | Description | Type |
File_id | The ID of the file to use for this request. | Text |
Return Values:
The File object matching the specified ID.
15. List files
Returns a list of files that belong to the user's organization.
Return Values:
A list of File objects.
16. Delete file
Delete a file.
Name | Description | Type |
File_id | The ID of the file to use for this request. | Text |
Return Values:
Deletion status.
17. Retrieve vector store
Retrieves a vector store.
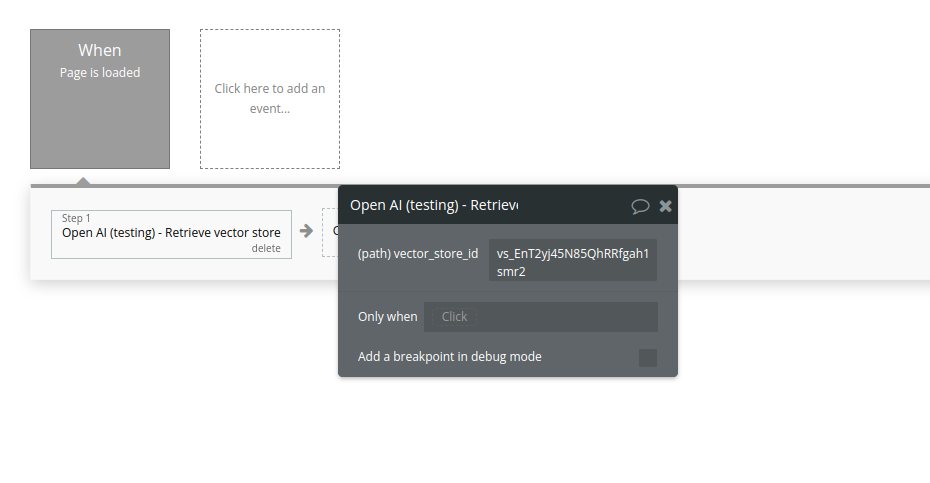
Name | Description | Type |
Vector_store_id | The ID of the vector store to retrieve. | Text |
Return Values:
The vector store object matching the specified ID.
18. Modify vector store
Modifies a vector store.
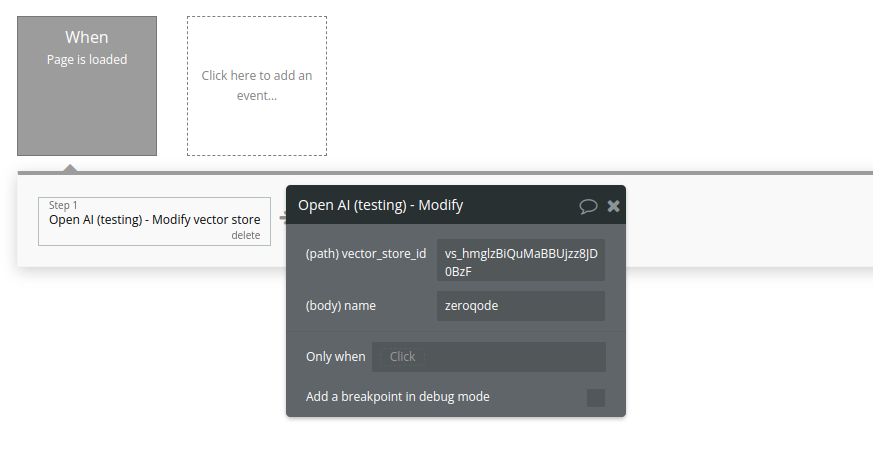
Name | Description | Type |
Vector_store_id | The ID of the vector store to modify. | Text |
Name | The name of the vector store. | Text |
Return Values:
The modified vector store object.
19. Delete vector store
Delete a vector store.
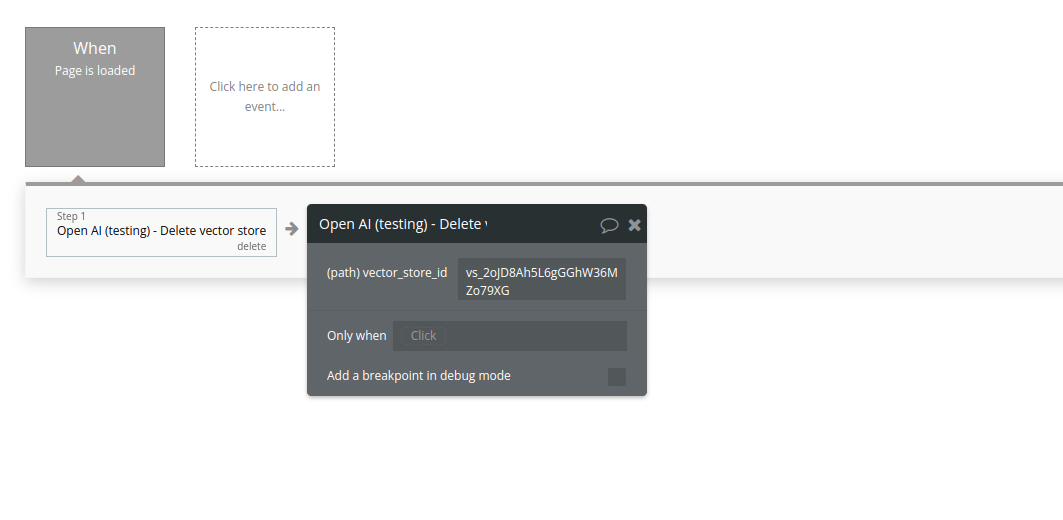
Name | Description | Type |
Vector_store_id | The ID of the vector store to delete. | Text |
Return Values:
Deletion status
20. Create vector store file
Create a vector store file by attaching a File to a vector store.
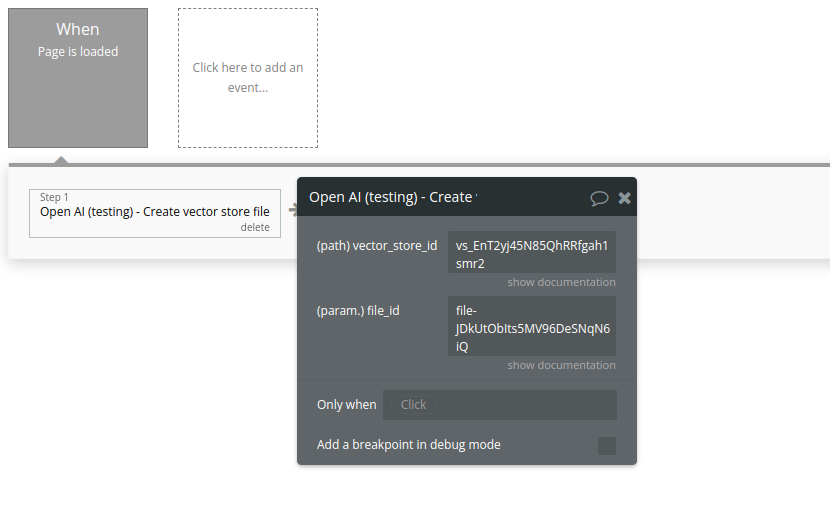
Name | Description | Type |
File_id | A File ID that the vector store should use. Useful for tools like file_search that can access files. | Text |
Vector_store_id | The ID of the vector store for which to create a File. | Text |
Return Values:
A vector store file object.
21. Delete vector store file
Delete a vector store file. This will remove the file from the vector store but the file itself will not be deleted.
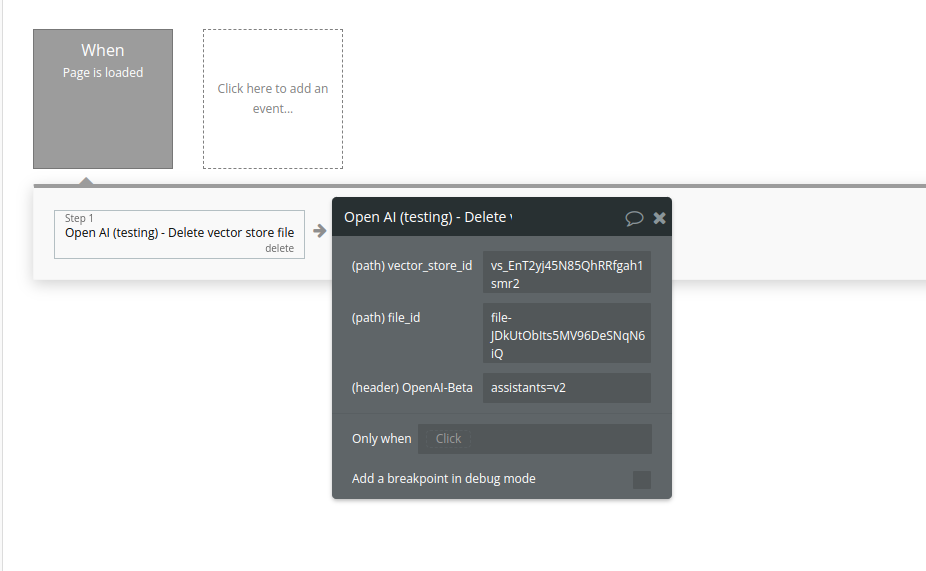
Name | Description | Type |
Vector_store_id | The ID of the vector store that the file belongs to. | Text |
File_id | The ID of the file to delete. | Text |
Return Values:
Deletion status
22.List vector store files
Returns a list of vector store files.
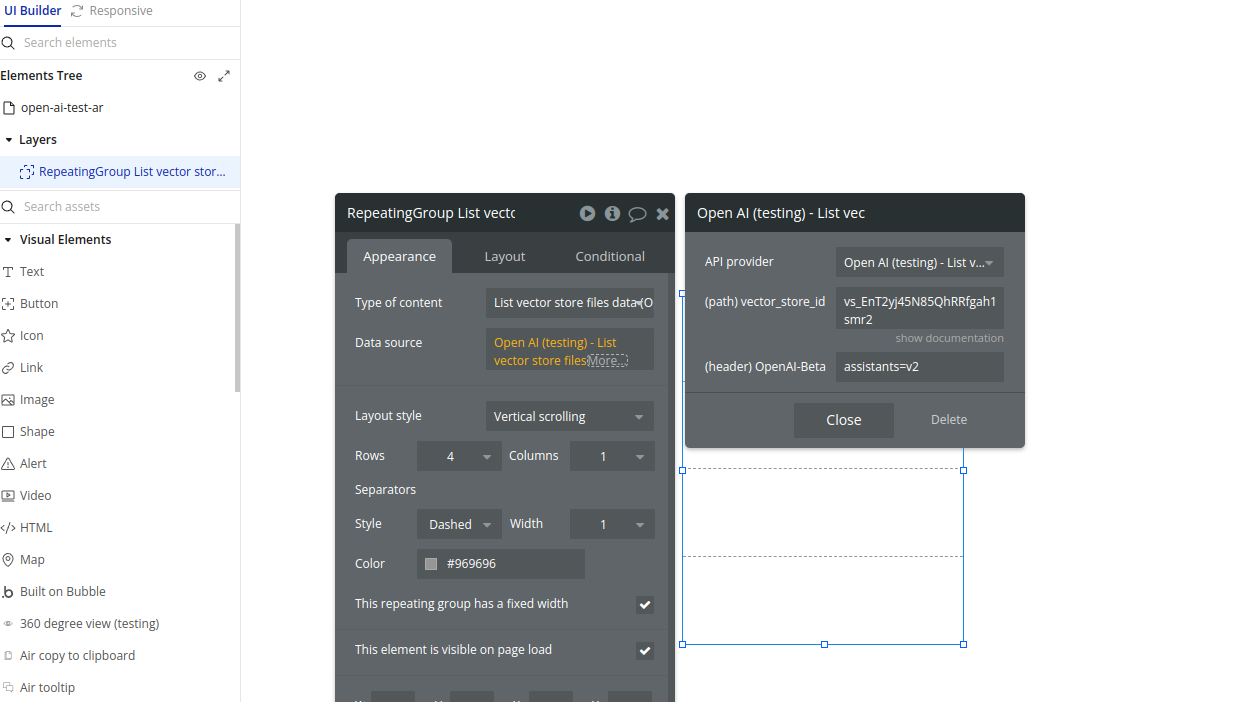
Name | Description | Type |
Vector_store_id | The ID of the vector store that the files belong to. | Text |
Return Values:
A list of vector store file objects.
23. Retrieve vector store file
Retrieves a vector store file.
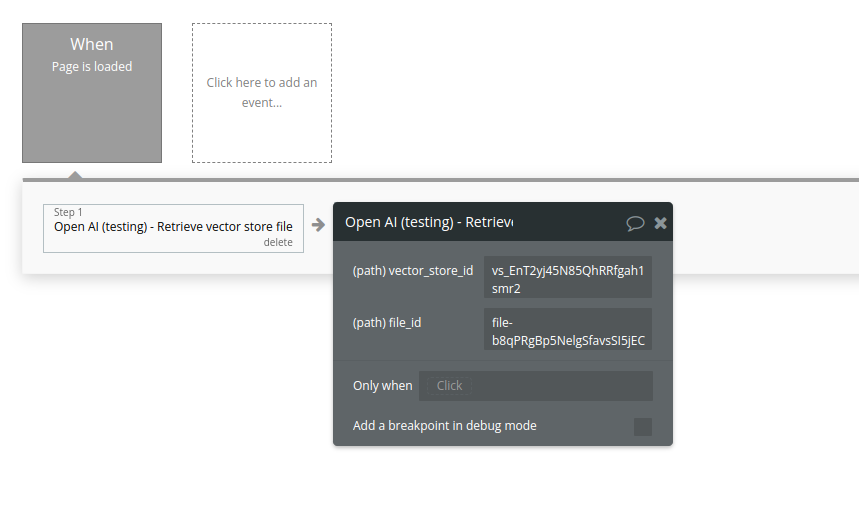
Name | Description | Type |
Vector_store_id | The ID of the vector store that the file belongs to. | Text |
File_id | The ID of the file being retrieved. | Text |
Return Values:
The vector store file object.
24. Create Assistant (function)
Create an assistant with a model and instructions(function tool)
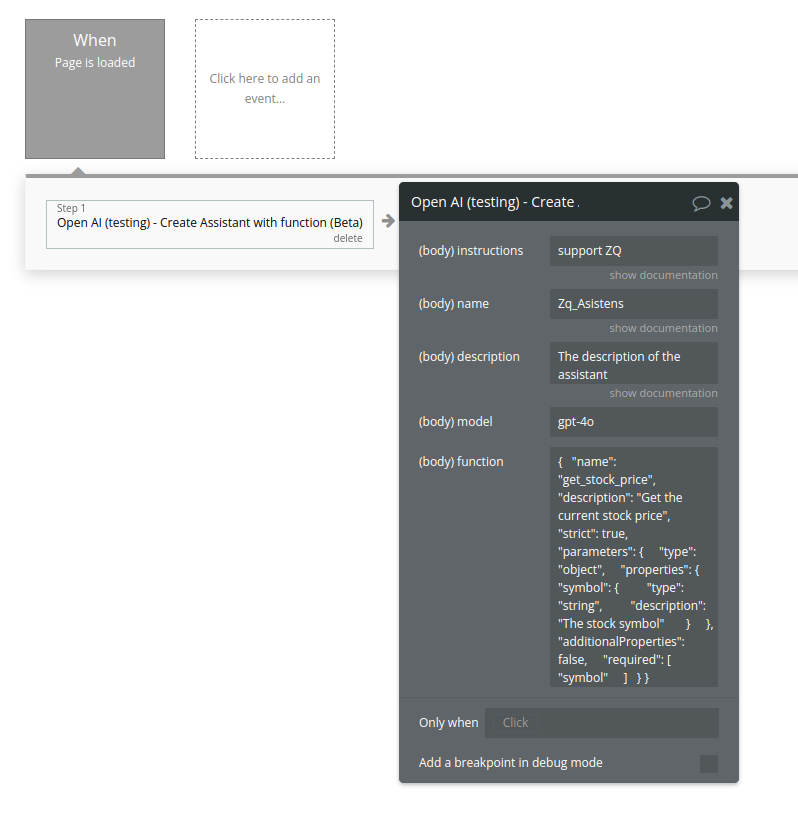
Name | Description | Type |
Instructions | The system instructions that the assistant uses. The maximum length is 32768 characters. | Text |
Name | The name of the assistant. The maximum length is 256 characters. | Text |
Description | The description of the assistant. The maximum length is 512 characters. | Text |
Model | ID of the model to use. You can use the List models API to see all of your available models, or see our Model overview for descriptions of them. | Text |
Function | description
string
Optional
A description of what the function does, used by the model to choose when and how to call the function.
name
string
Required
The name of the function to be called. Must be a-z, A-Z, 0-9, or contain underscores and dashes, with a maximum length of 64.
parameters
object
Optional
The parameters the functions accepts, described as a JSON Schema object. See the guide for examples, and the JSON Schema reference for documentation about the format.
Omitting parameters defines a function with an empty parameter list.
strict
boolean or null
Optional
Defaults to false
Whether to enable strict schema adherence when generating the function call. If set to true, the model will follow the exact schema defined in the parameters field. Only a subset of JSON Schema is supported when strict is true. Learn more about Structured Outputs in the function calling guide. | Text |
Return Values:
An assistant object.
25. Modify assistant (function)
Modifies an assistant with function
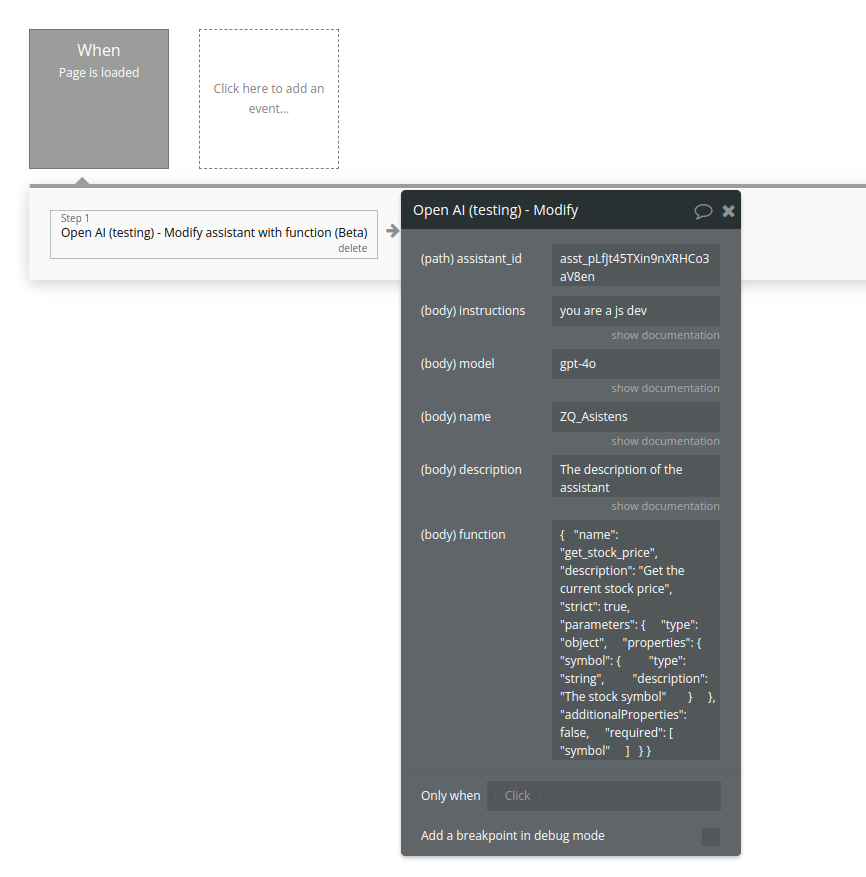
Name | Description | Type |
Assistant_id | The ID of the assistant to modify. | Text |
Instructions | The system instructions that the assistant uses. The maximum length is 32768 characters. | Text |
Model | ID of the model to use. You can use the List models API to see all of your available models, or see our Model overview for descriptions of them. | Text |
Name | The name of the assistant. The maximum length is 256 characters. | Text |
Description | The description of the assistant. The maximum length is 512 characters. | Text |
Function | Please see the call above for description | Text |
Return Values:
The modified assistant object.
26. Create Assistant (Code interpreter)
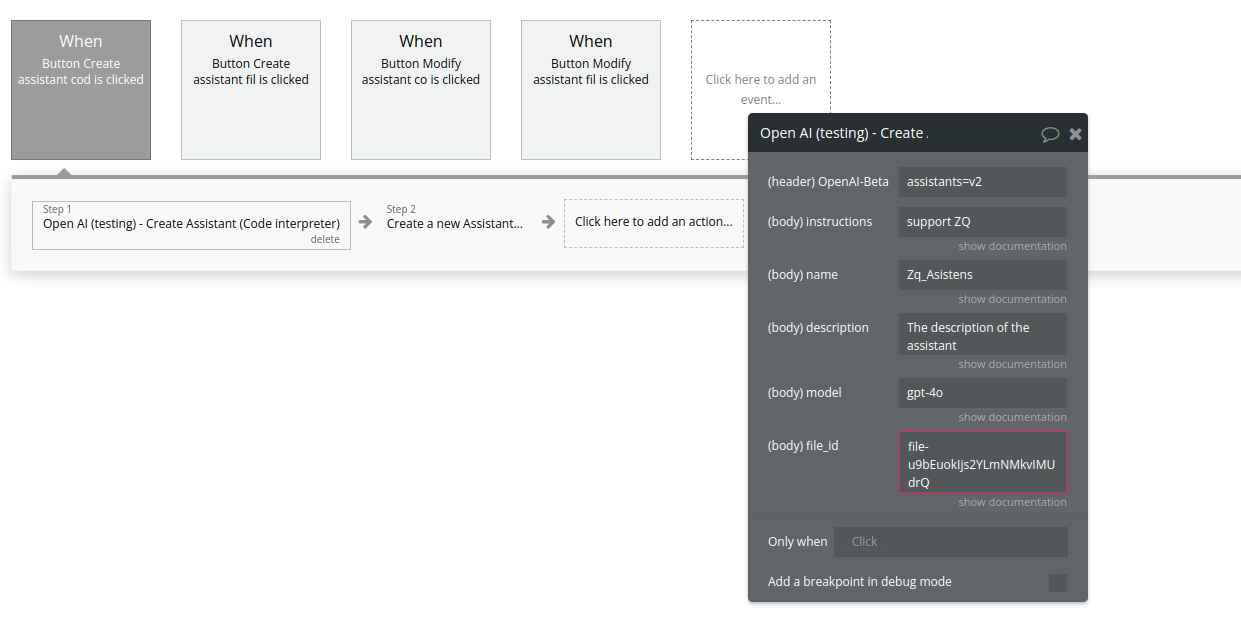
Name | Description | Type |
Instructions | The system instructions that the assistant uses. The maximum length is 32768 characters. | Text |
Name | The name of the assistant. The maximum length is 256 characters. | Text |
Description | The description of the assistant. The maximum length is 512 characters. | Text |
Model | ID of the model to use. You can use the List models API to see all of your available models, or see our Model overview for descriptions of them. | Text |
File_id | A list of file IDs made available to the code_interpreter tool. There can be a maximum of 20 files associated with the tool. | Text |
Return Values:
An assistant object.
27. Modify assistant (Code interpreter)
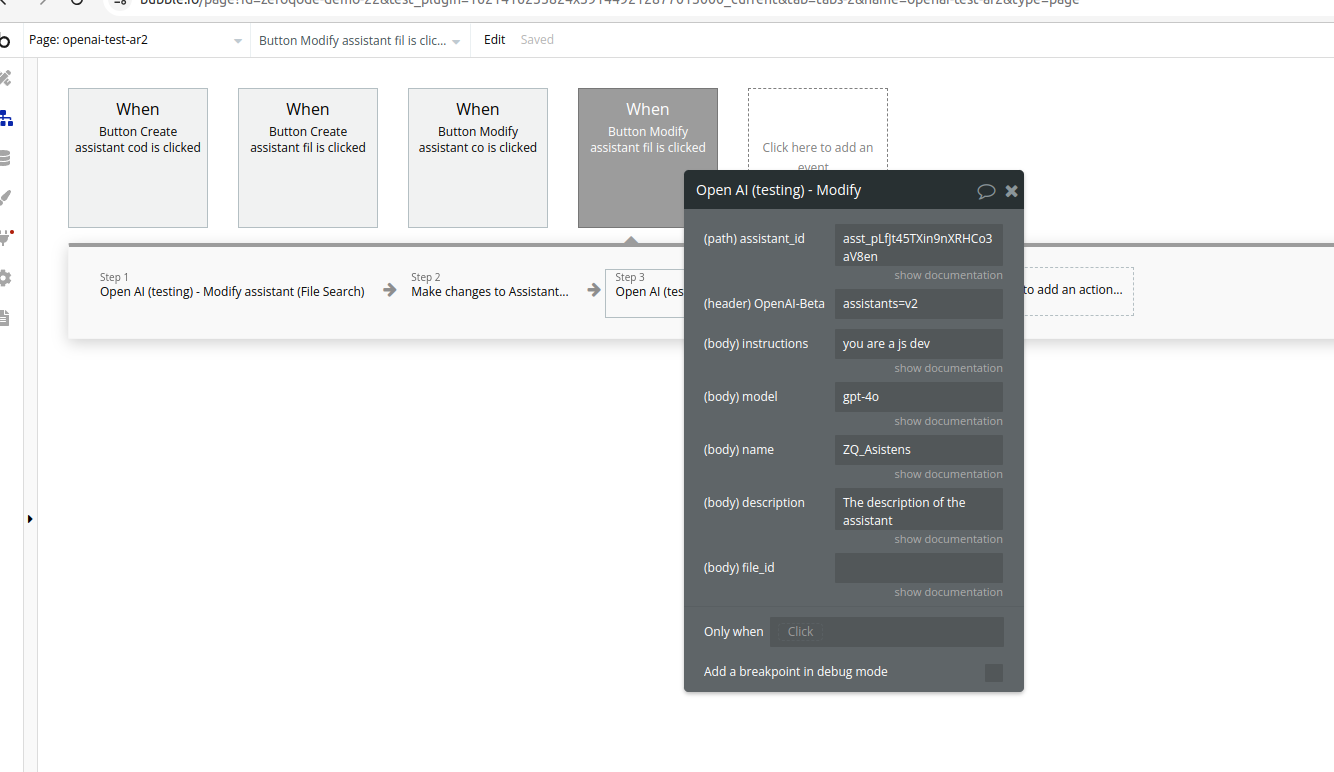
Name | Description | Type |
Assistant_id | The ID of the assistant to modify. | Text |
Instructions | The system instructions that the assistant uses. The maximum length is 32768 characters. | Text |
Model | ID of the model to use. You can use the List models API to see all of your available models, or see our Model overview for descriptions of them. | Text |
Name | The name of the assistant. The maximum length is 256 characters. | Text |
Description | The description of the assistant. The maximum length is 512 characters. | Text |
File_id | A list of file IDs made available to the code_interpreter tool. There can be a maximum of 20 files associated with the tool. | Text |
28. Create Assistant (File Search)
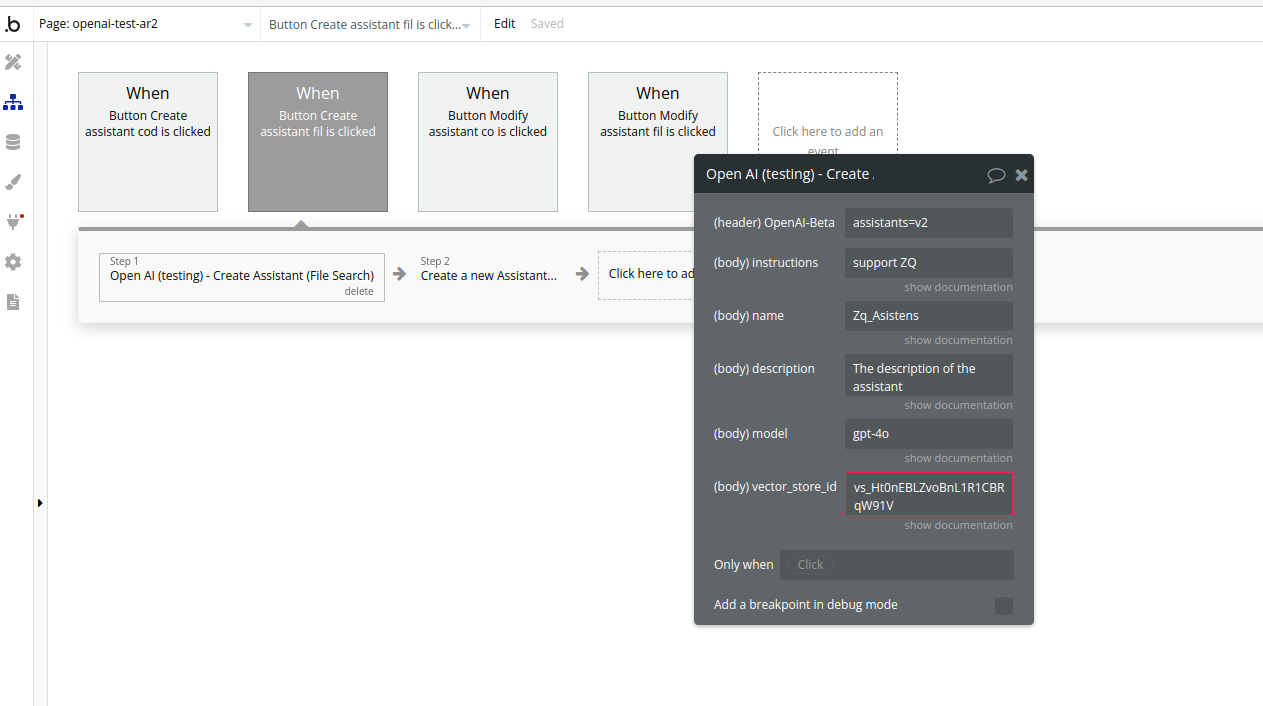
Name | Description | Type |
Instructions | The system instructions that the assistant uses. The maximum length is 32768 characters. | Text |
Name | The name of the assistant. The maximum length is 256 characters. | Text |
Description | The description of the assistant. The maximum length is 512 characters. | Text |
Model | ID of the model to use. You can use the List models API to see all of your available models, or see our Model overview for descriptions of them. | Text |
Vector_store_ids | The vector store attached to this assistant. There can be a maximum of 1 vector store attached to the assistant. | Text |
29. Modify assistant (File Search)
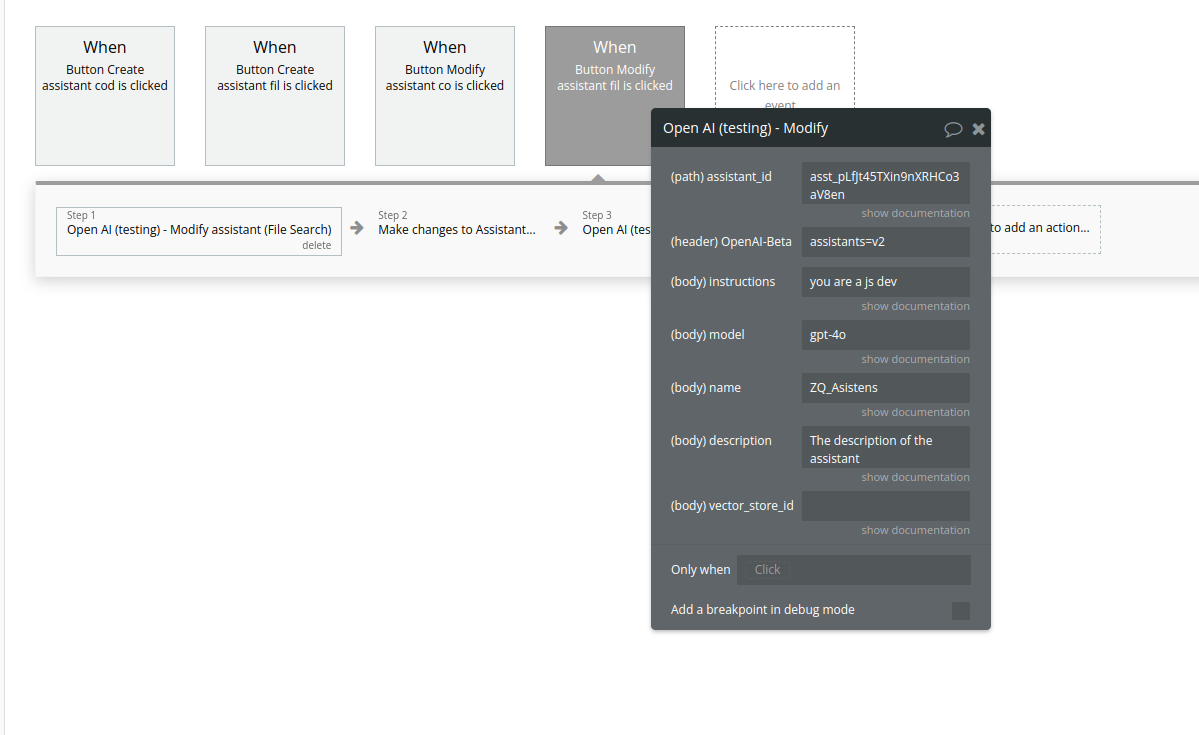
Name | Description | Type |
Assistant_id | The ID of the assistant to modify. | Text |
Instructions | The system instructions that the assistant uses. The maximum length is 32768 characters. | Text |
Model | ID of the model to use. You can use the List models API to see all of your available models, or see our Model overview for descriptions of them. | Text |
Name | The name of the assistant. The maximum length is 256 characters. | Text |
Description | The description of the assistant. The maximum length is 512 characters. | Text |
Vector_store_ids | The vector store attached to this assistant. There can be a maximum of 1 vector store attached to the assistant. | Text |