
✅
Link to the plugin page: https://zeroqode.com/plugin/replicate-ai-modelsplugin-for-bubble-1738947983097x768540118909296900
Demo to preview the plugin:
✅
Introduction
The Replicate AI plugin enables you to harness the power of the Replicate AI platform and its models for advanced machine-learning tasks. This plugin allows you to generate, manage, and retrieve predictions using various AI models hosted on Replicate.
💡
Every time you run a model, you're creating a prediction. A prediction is the result generated by an AI model in response to specific inputs provided by the user. It involves processing the input data—such as a text prompt, image, or other parameters—through a trained model to produce an output.
💡
Input and output (including any files) are automatically deleted after an hour for any predictions created through the API, so you must save a copy of any files in the output if you'd like to continue using them.
Some models execute rapidly and may provide results in just a few milliseconds. However, more complex models, such as those generating images from text prompts, may require significantly more time to complete.
To handle this effectively:
- Wait for Response: You can configure the action to wait for the response. While this works well for faster predictions, it may not suffice for models that take longer to process.
- Using a Webhook: For lengthy predictions, it is highly recommended to provide a webhook URL. This allows the model to send updates to your server as soon as the prediction is ready, ensuring you don't miss the result.
- Manual Retrieval: If you prefer not to use a webhook or are unable to, you can manually query the prediction status later to retrieve the output once it's completed.
Available Models In The Plugin
- A generative model for creating high-quality images from textual prompts.
- Use Case: Generating artistic, photorealistic, or abstract visuals.
2. GFPGAN
- A generative model designed to enhance and restore facial features in images.
- Use Case: Improving image quality, restoring old or damaged photos.
3. SDXL
- An advanced version of the Stable Diffusion model with extended capabilities.
- Use Case: Producing ultra-high-resolution images with finer details.
4. Music-01
- A model specialized in generating music or audio based on input prompts and references.
- Use Case: Composing music tracks or audio samples.
- A premium model for advanced generative tasks requiring high fidelity and precision.
- Use Case: Creating cutting-edge visuals, animations, or simulations.
Prerequisites
💡
To create a Replicate AI account, you first need to have a GitHub account. After setting up your GitHub account, you can sign up for Replicate AI using GitHub for authentication.
How to setup
- Create an account on Replicate AI or sign in to an existing one.
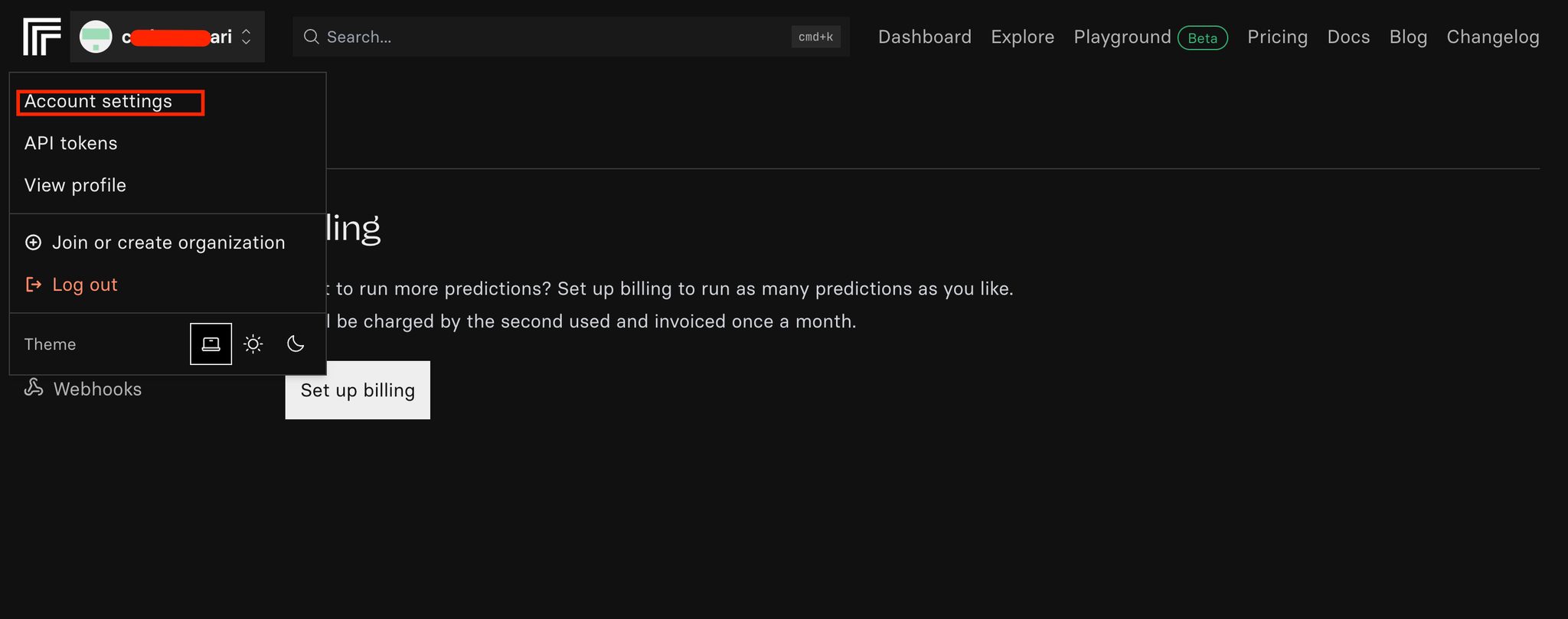
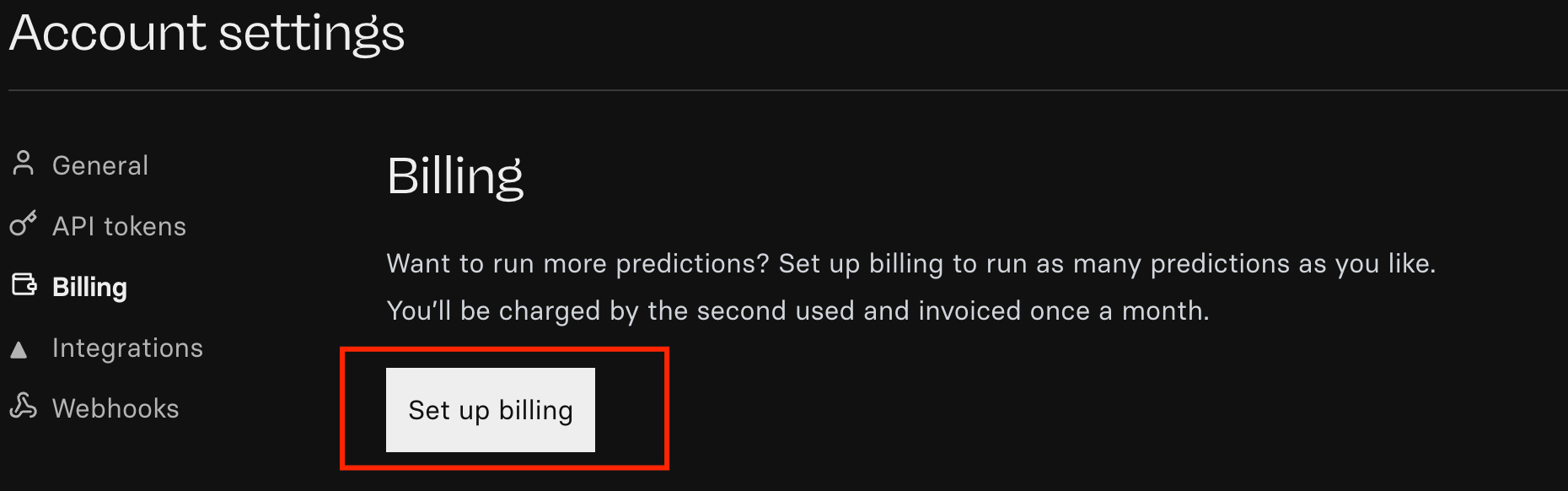
2. Set up the billing for the account, in the account “Setting” tab → “Billing” section.
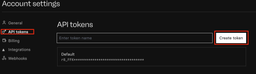
- Go to “API tokens” tab and create a token.
- Copy the token and set it up in the plugin settings on bubble page for secure usage of the Replicate AI.
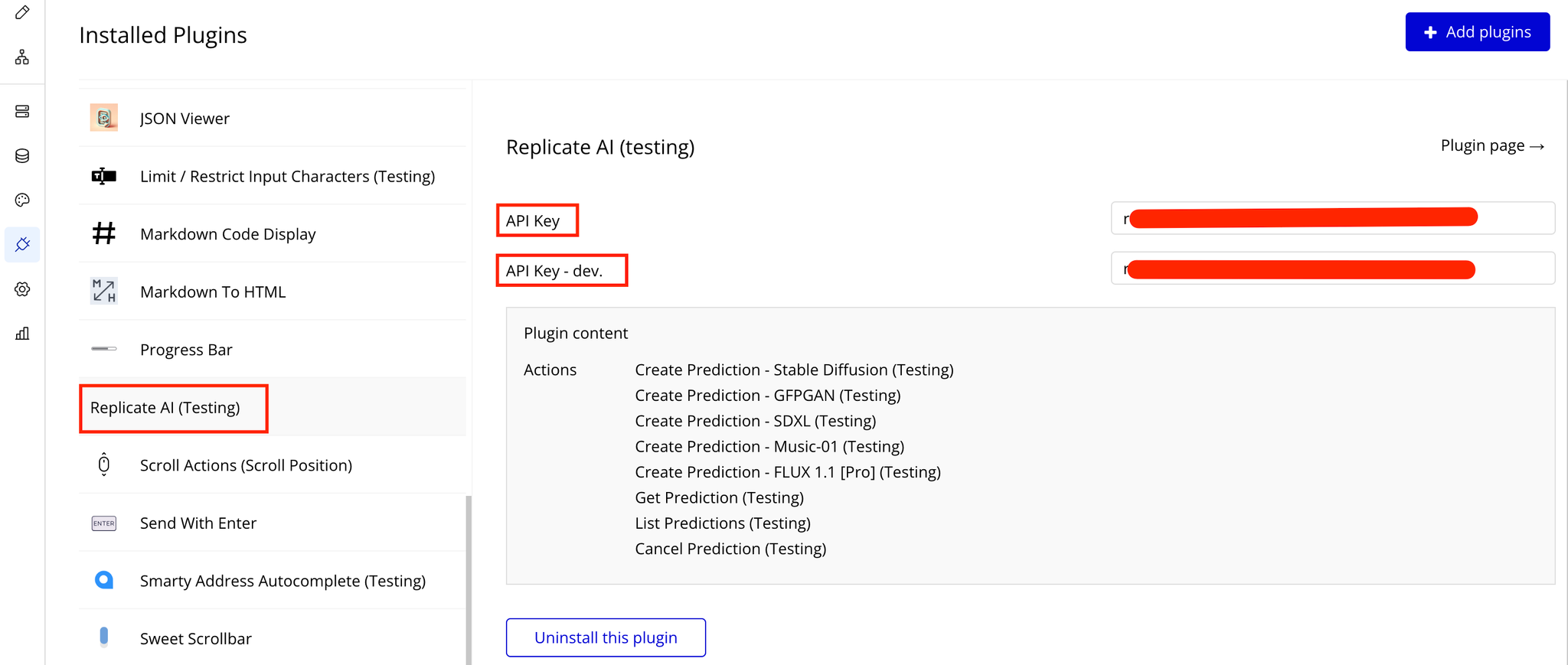
Plugin Data/Action Calls (API Calls only)
Create Prediction - Stable Diffusion
This action generates images using the Stable Diffusion model on the Replicate AI platform. Stable Diffusion is a state-of-the-art AI model designed for generating high-quality images based on text prompts.
💡
The API key field is optional. It should only be specified if dynamic key switching is required within the application. The key should be set only in the plugin settings in all other cases.
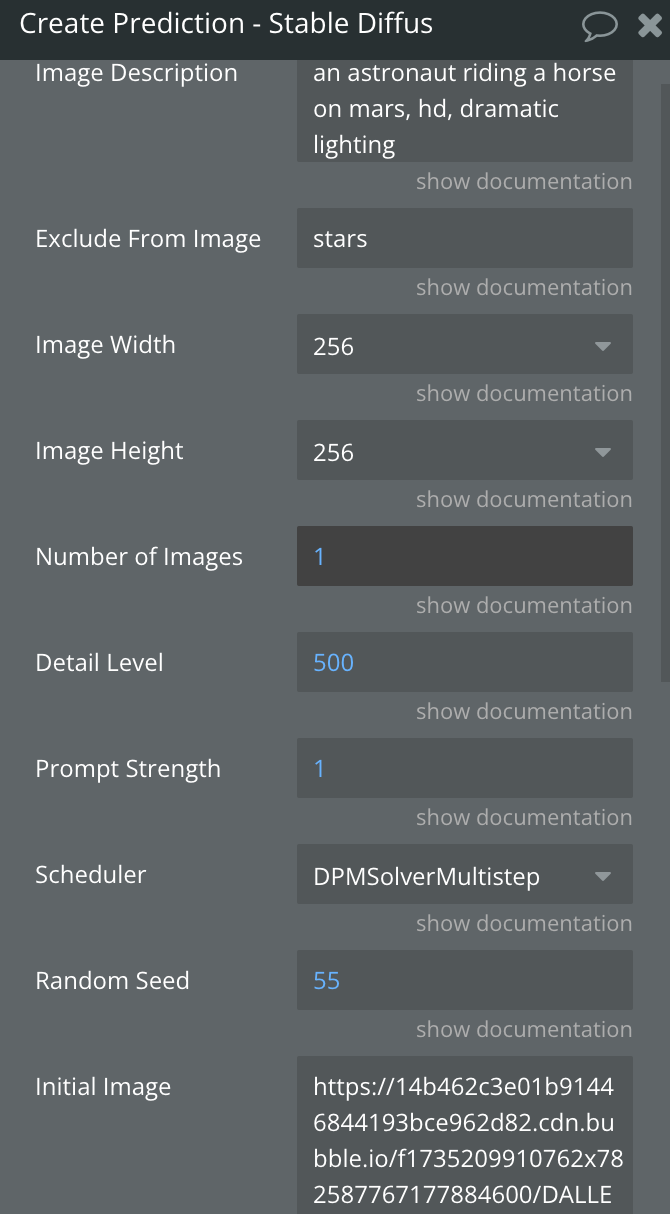
Fields:
Name | Description | Type |
Image Description | A textual prompt describing the desired image to be generated. This is the main input guiding the AI to create the image. | Text |
Exclude From Image | (Optional) Text specifying elements or details that should not appear in the generated image. | Text |
Image Width | The width of the generated image in pixels. Must be a multiple of 64. | Dropdown (64, 128, 192, 256, 320, 384, 448, 512, 576, 640, 704, 768, 832, 896, 960, 1024) |
Image Height | The height of the generated image in pixels. Must be a multiple of 64. | Dropdown (64, 128, 192, 256, 320, 384, 448, 512, 576, 640, 704, 768, 832, 896, 960, 1024) |
Number of Images | The number of images to be generated. Specifies how many variations of the image will be created.(minimum: 1, maximum: 4) | Number |
Detail Level | (Optional) Specifies the number of inference steps, which control the level of detail and quality in the generated image. Higher values generally produce more detailed images but take longer to process. (minimum: 1, maximum: 500) | Number |
Prompt Strength | (Optional) Determines how strongly the model adheres to the input prompt when generating the image. A higher value prioritizes the prompt more strictly.(from 0.0 to 1.0) | Number |
Scheduler | The scheduler defines the type of diffusion process to use during image generation. Different schedulers have different methods of gradually transforming random noise into the final image. Some are more computationally efficient, while others may generate more detailed or varied results. The choice of scheduler can affect the style and complexity of the generated image.
Details about schedulers check below. | Dropdown (DDIM, K_EULER, DPMSolverMultistep, K_EULER_ANCESTRAL, PNDM, KLMS) |
Random Seed | (Optional) Any integer number. It serves to initialize the random number generator used in the image generation process. When you set a specific seed, it ensures that the model produces the same output every time you use that seed with the same input parameters. This is useful for reproducibility. | Number |
Initial Image | (Optional) A base image provided as a starting point for image generation. The model will use this image as a reference. The image must be publicly accessible via a URL for the model to retrieve and process it. Ensure that the URL allows direct access without requiring authentication or additional headers. | Text (URL) |
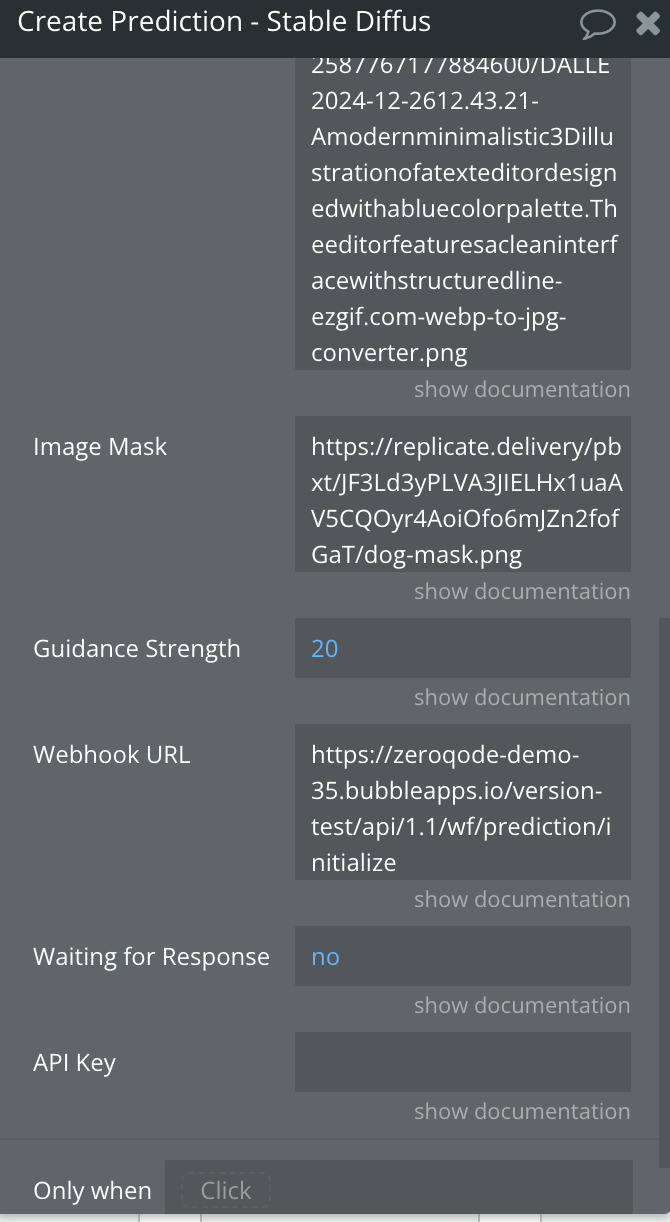
Image Mask | (Optional) A mask image used to specify regions of the initial image to be preserved or modified. Useful for inpainting tasks. The image must be publicly accessible via a URL for the model to retrieve and process it. Ensure that the URL allows direct access without requiring authentication or additional headers.
Check below how a image mask should look in order to work properly. | Text (URL) |
Guidance Strength | (Optional) Specifies the level of influence the input prompt has when an initial image is provided (minimum: 1, maximum: 20). | Number |
Webhook URL | (Optional) A URL to receive the prediction result asynchronously. The system will send the results to this URL when ready. | Text (URL) |
Waiting for Response | Specifies whether the action should wait for the prediction to complete and return the processed image immediately. | Yes/No |
API Key | (Optional) The API key from your Replicate AI account, used to authenticate requests. Set directly in this field if required for flexibility, but leave it empty here and configure it securely in the plugin settings for safe storage. | Text |
Return values:
Name | Description | Type |
Prediction ID | The unique identifier for the prediction, used to retrieve its status or output. | Text |
Result Images | The generated image or images, returned when the prediction is successful and completed (only if Waiting for Response is set to “Yes”). | Text List |
Status | The current status of the prediction | Text |
Error | Any error message encountered during the process. | Text |
How a Image Mask must look

Image Mask - a black-and-white (grayscale) image where:
- Black areas (RGB: 0, 0, 0): These regions will be protected and remain unchanged.
- White areas (RGB: 255, 255, 255): These regions will be modified by the model.
Schedulers Details
1. DDIM (Denoising Diffusion Implicit Models)
- Description:DDIM is a deterministic scheduler that skips unnecessary steps in the diffusion process, making the generation faster while retaining high-quality results.
- Key Features:
- Faster generation compared to traditional diffusion methods.
- Produces smooth and high-quality outputs.
- Suitable for applications requiring speed and consistency.
2. K_EULER (Euler Scheduler)
- Description:K_EULER is a classic scheduler using the Euler method for solving differential equations. It balances between quality and computational efficiency.
- Key Features:
- Moderately fast.
- Produces detailed images with good consistency.
- A reliable choice for general use cases.
3. DPMSolverMultistep (Denoising Diffusion Probabilistic Solver Multistep)
- Description:This is an advanced scheduler designed to accelerate generation while maintaining precision. It uses multi-step updates to solve the denoising process more efficiently.
- Key Features:
- Highly efficient and faster than many other schedulers.
- Maintains excellent output quality.
- Ideal for time-sensitive tasks with a focus on precision.
4. K_EULER_ANCESTRAL (Euler Ancestral Scheduler)
- Description:A variant of the Euler scheduler, it introduces random noise at each step to allow for more diverse and creative outputs.
- Key Features:
- Suitable for generating artistic or imaginative images.
- May sacrifice some consistency for creativity.
- Works well for experimentation with unique styles.
5. PNDM (Pseudo Numerical Diffusion Model)
- Description:PNDM is a pseudo-numerical approach that bridges traditional numerical methods with diffusion models. It aims to improve generation speed without compromising on quality.
- Key Features:
- Fast and efficient.
- Balanced output quality.
- Good for general-purpose applications.
6. KLMS (LMS Discrete Scheduler or Karras LMS)
- Description:KLMS is a scheduler based on the Linear Multistep Method, optimized with techniques from Karras (a popular researcher in the field). It provides high-quality results by focusing on the denoising process's accuracy.
- Key Features:
- Generates highly detailed and accurate images.
- Slightly slower than some other schedulers but worth it for quality.
- Excellent for applications requiring precise outputs.
Create Prediction - GFPGAN
This action uses the GFPGAN (Generative Facial Prior GAN) model to restore or enhance facial details in images. It takes an input image and processes it to improve facial quality, correct distortions, and enhance clarity while preserving the overall structure.
💡
The API key field is optional. It should only be specified if dynamic key switching is required within the application. The key should be set only in the plugin settings in all other cases.
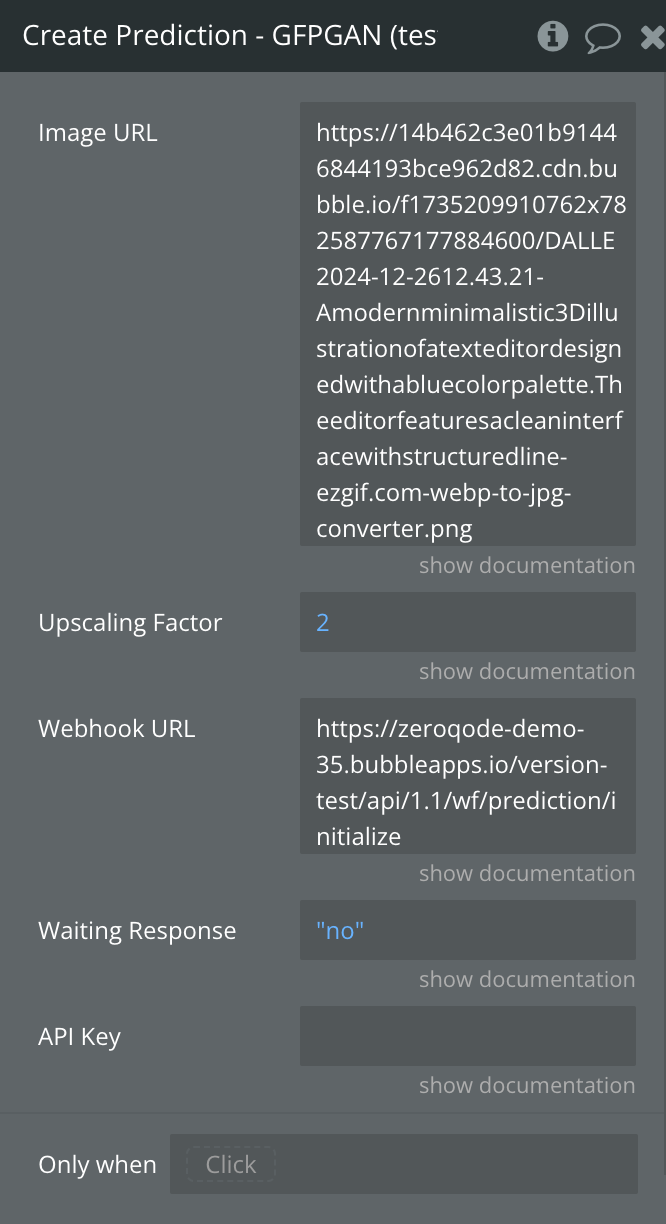
Fields:
Name | Description | Type |
Image URL | The direct URL of the image to be processed. This should be a publicly accessible URL pointing to an image file. The action uses this URL to fetch the image for upscaling. Ensure the image is accessible without authentication. | Text |
Upscaling Factor | The factor by which the image will be upscaled. For example, a value of 2 means the image dimensions will double, and a value of 4 will quadruple the dimensions. The larger the factor, the higher the resolution of the resulting image, but it may increase processing time. | Number |
Webhook URL | (Optional) A URL to receive the prediction result asynchronously. The system will send the results to this URL when ready. | Text (URL) |
Waiting for Response | Specifies whether the action should wait for the prediction to complete and return the processed image immediately. | Yes/No |
API Key | (Optional) The API key from your Replicate AI account, used to authenticate requests. Set directly in this field if required for flexibility, but leave it empty here and configure it securely in the plugin settings for safe storage. | Text |
Return values:
Name | Description | Type |
Prediction ID | The unique identifier for the upscaling prediction request. | Text |
Result Image | The URL of the upscaled image, returned when the prediction is successful and completed (only if Waiting for Response is set to “Yes”). | Text |
Status | The status of the upscaling process. | Text |
Error | Any error message that occurred during the prediction creation process. | Text |
Create Prediction - SDXL
This action initiates a prediction request using the SDXL model, which generates images based on a provided description or prompt. You can configure various parameters such as image dimensions, prompt strength, and more to customize the generated output.
💡
The API key field is optional. It should only be specified if dynamic key switching is required within the application. The key should be set only in the plugin settings in all other cases.

Fields:
Name | Description | Type |
Image Prompt | A text-based description of the image you want to generate. This is the primary input that guides the model to create an image based on your prompt. | Text |
Negative Prompt | (Optional) A text description of elements or characteristics to avoid in the generated image. | Text |
Initial Image | (Optional) A URL to an initial image that serves as a starting point for the generation. The provided image must be accessible via a public URL. | Text (URL) |
Image Mask | (Optional) Masks define which areas of the "Initial Image" should remain unchanged or receive modifications. Input mask for inpaint mode. Black areas will be preserved, white areas will be inpainted. | Text (URL) |
Image Width | (Optional) The desired width of the generated image in pixels. | Dropdown (64, 128, 192, 256, 320, 384, 448, 512, 576, 640, 704, 768, 832, 896, 960, 1024) |
Image Height | (Optional) The desired height of the generated image in pixels. | Dropdown (64, 128, 192, 256, 320, 384, 448, 512, 576, 640, 704, 768, 832, 896, 960, 1024) |
Number of Images | The number of image variations to generate based on the prompt. (minimum: 1, maximum: 4) | Number |
Prompt Strength | Set how much influence the prompt should have compared to the initial image (if provided). (minimum: 0, maximum: 1)
1.0 corresponds to full destruction of information in image. | Number |
Prompt Guidance Strength | (Optional) A parameter controlling how strongly the prompt influences the generated image. Higher values lead to images that more closely match the prompt.(minimum: 1, maximum: 50) | Number |
Inference Steps | (Optional) Controls the number of steps the model takes to refine the image. Higher values improve quality but increase computation time. Suitable for detailed and high-quality results. (minimum: 1, maximum: 500) | Number |
Sampling Scheduler | Selects the algorithm used for sampling during image generation. Different schedulers produce distinct styles or qualities.
Details about schedulers check below. | Dropdown (
DDIM,
DPMSolverMultistep,
HeunDiscrete,
KarrasDPM,
K_EULER_ANCESTRAL,
K_EULER,
PNDM
) |
Random Seed | (Optional) A seed value to control randomness in image generation. Use the same seed to replicate results. Leaving this blank will generate random outputs. | Number |
Refinement Model | (Optional) Specifies the model used for refining the image after the initial generation. Specifies the model used for refining the image after the initial generation.
Check details below. | Dropdown (no_refiner,
expert_ensemble_refiner,
base_image_refiner) |
High Noise Fraction | (Optional) Controls the amount of noise introduced during image generation. For expert_ensemble_refiner, the fraction of noise to use. (minimum: 0, maximum: 1) | Number |
Refine Steps | (Optional) The number of steps to use in the refinement process. Higher values enhance refinement but take longer. | Number |
Add Watermark | Applies a watermark to enable determining if an image is generated in downstream applications. If you have other provisions for generating or deploying images safely, you can use this to disable watermarking. | Yes/No |
LoRA Scale | (Optional) LoRA (Low-Rank Adaptation) is a method for fine-tuning large pre-trained models more efficiently. Instead of retraining the entire model, LoRA adds small, low-rank layers that adapt the model for specific tasks. The LoRA scale controls how much influence these low-rank layers have on the final output. A higher scale means the LoRA adaptation has more influence, while a lower scale means the original model's behavior dominates. (minimum: 0, maximum: 1) | Number |
Webhook URL | (Optional) A URL to receive the prediction result asynchronously. The system will send the results to this URL when ready. | Text (URL) |
Waiting for Response | Specifies whether the action should wait for the prediction to complete and return the processed image immediately. | Yes/No |
API Key | (Optional) The API key from your Replicate AI account, used to authenticate requests. Set directly in this field if required for flexibility, but leave it empty here and configure it securely in the plugin settings for safe storage. | Text |
Return values:
Name | Description | Type |
Prediction ID | The unique identifier for the prediction, used to retrieve its status or output. | Text |
Result Images | The generated image or images, returned when the prediction is successful and completed (only if Waiting for Response is set to “Yes”). | Text List |
Status | The current status of the prediction. | Text |
Error | Any error message encountered during the process. | Text |
How a Image Mask must look

Image Mask - a black-and-white (grayscale) image where:
- Black areas (RGB: 0, 0, 0): These regions will be protected and remain unchanged.
- White areas (RGB: 255, 255, 255): These regions will be modified by the model.
Schedulers Details
1. DDIM (Denoising Diffusion Implicit Models)
- Description:
DDIM is a non-Markovian scheduler that enables faster diffusion processes, while maintaining quality and providing flexibility. It's known for producing smoother transitions and more controlled generations.
- Usage:
Suitable for those seeking quicker, but still detailed results in generative tasks, especially in image creation from text prompts.
2. DPMSolverMultistep
- Description:
This scheduler uses the DPM-Solver to efficiently solve diffusion problems, optimizing for high-quality results with fewer steps. It balances accuracy and computational efficiency by minimizing the number of steps needed to converge.
- Usage:
Best for those looking for a balance between quality and performance while reducing the computational load of multiple diffusion steps.
3. HeunDiscrete
- Description:
HeunDiscrete is a method designed for faster diffusion solving by using a discrete version of the Heun method, which provides good accuracy with lower computational complexity.
- Usage:
Ideal for scenarios where you want relatively faster image generation without sacrificing much quality in the process.
4. KarrasDPM
- Description:
KarrasDPM is a scheduler designed specifically to work well with the Karras diffusion models, focusing on stable and high-quality results by carefully balancing the noise reduction process.
- Usage:
Typically used for tasks that require high-quality results and optimal performance, particularly with Karras-based models.
5. K_EULER_ANCESTRAL
- Description:
This is an ancestral variant of the Euler method used for solving diffusion processes. It’s known for generating high-quality images by focusing on the ancestral generation of the image.
- Usage:
Best for those looking for more coherent and less noisy outputs, particularly when high precision is needed in generative tasks.
6. K_EULER
- Description:
The K_EULER scheduler uses the classic Euler method for diffusion solving, providing a reliable method for generating high-quality results, especially when the model needs to generate images with careful control over the diffusion steps.
- Usage:
A solid choice when a straightforward, well-tested approach is desired without too many complex adjustments, perfect for most general image generation tasks.
7. PNDM (Pseudo Numerical Methods for Diffusion Models)
- Description:
PNDM uses pseudo-numerical methods to improve the stability and efficiency of the diffusion process, making it faster while maintaining the high quality of generated outputs.
- Usage:
Ideal for those who need quick results with good quality, balancing computational efficiency and accuracy in diffusion models.
Available Refinement Models:
1. no_refiner
- Description:
This option skips any refinement process, and the generated image is returned as-is after the initial generation. No further enhancements are applied to the image.
- Usage:
Choose this option if you prefer a quicker result without any additional refinement or if the image generated already meets your expectations without the need for further improvements.
2. expert_ensemble_refiner
- Description:
This refinement model utilizes an ensemble of expert models to enhance the image after its initial generation. The "expert_ensemble_refiner" combines different specialized models that work together to refine details, remove noise, and add sharpness, resulting in a higher-quality final image.
- Usage:
Ideal for users looking for advanced refinement, producing images with enhanced details and greater accuracy, especially when high-quality, polished output is needed.
3. base_image_refiner
- Description:
The "base_image_refiner" model focuses on enhancing the base image itself by applying subtle refinements that improve its overall quality and coherence. It works by taking the initially generated image and fine-tuning it to correct minor imperfections, enhance textures, and improve visual consistency.
- Usage:
Best used when the goal is to improve the general quality of the image and make it more visually appealing without introducing major stylistic changes.
Create Prediction - Music-01
This action generates music using the Music-01 model. The model can create original music based on the provided input parameters.
💡
The API key field is optional. It should only be specified if dynamic key switching is required within the application. The key should be set only in the plugin settings in all other cases.

Fields:
Name | Description | Type |
Lyrics | Lyrics with optional formatting. You can use a newline to separate each line of lyrics. You can use two newlines to add a pause between lines. You can use double hash marks (##) at the beginning and end of the lyrics to add accompaniment. Maximum 350 to 400 characters. | Text |
Reference Song File | A publicly accessible URL of a reference song file, should contain music and vocals. Must be a .wav or .mp3 file longer than 15 seconds. | Text (URL) |
Reference Voice File | (Optional) A publicly accessible URL of a voice file to be used as a reference for vocals in the generated music.. Must be a .wav or .mp3 file longer than 15 seconds. If only a voice reference is given, an a cappella vocal hum will be generated. | Text (URL) |
Reference Instrumental File | (Optional) A publicly accessible URL of an instrumental track to be used as a reference for the instrumental parts of the music. Must be a .wav or .mp3 file longer than 15 seconds. If only an instrumental reference is given, a track without vocals will be generated. | Text (URL) |
Sample Rate | Specifies the audio sample rate (e.g., 44100 Hz) to determine the resolution and quality of the generated audio. | Dropdown (16000,
24000,
32000,
44100) |
Bitrate | Defines the audio bitrate (e.g., 128 kbps or 320 kbps) for the output file. Higher bitrates result in better audio quality. | Dropdown (32000,
64000,
128000,
256000) |
Webhook URL | (Optional) A URL to receive the prediction result asynchronously. The system will send the results to this URL when ready. | Text (URL) |
API Key | (Optional) The API key from your Replicate AI account, used to authenticate requests. Set directly in this field if required for flexibility, but leave it empty here and configure it securely in the plugin settings for safe storage. | Text |
Return values:
Name | Description | Type |
Prediction ID | The unique identifier for the upscaling prediction request. | Text |
Status | Status of the music generation process, such as "succeeded" or "failed".T | Text |
Error | Any error message that occurred during the prediction creation process. | Text |
Create Prediction - FLUX 1.1 [Pro]
This action is used to create a new image generation prediction request using the FLUX 1.1 [Pro] model. The model takes various input parameters like prompts, initial image, and optional configurations to generate the desired image. Text-to-image model with excellent image quality, prompt adherence, and output diversity.
💡
The API key field is optional. It should only be specified if dynamic key switching is required within the application. The key should be set only in the plugin settings in all other cases.
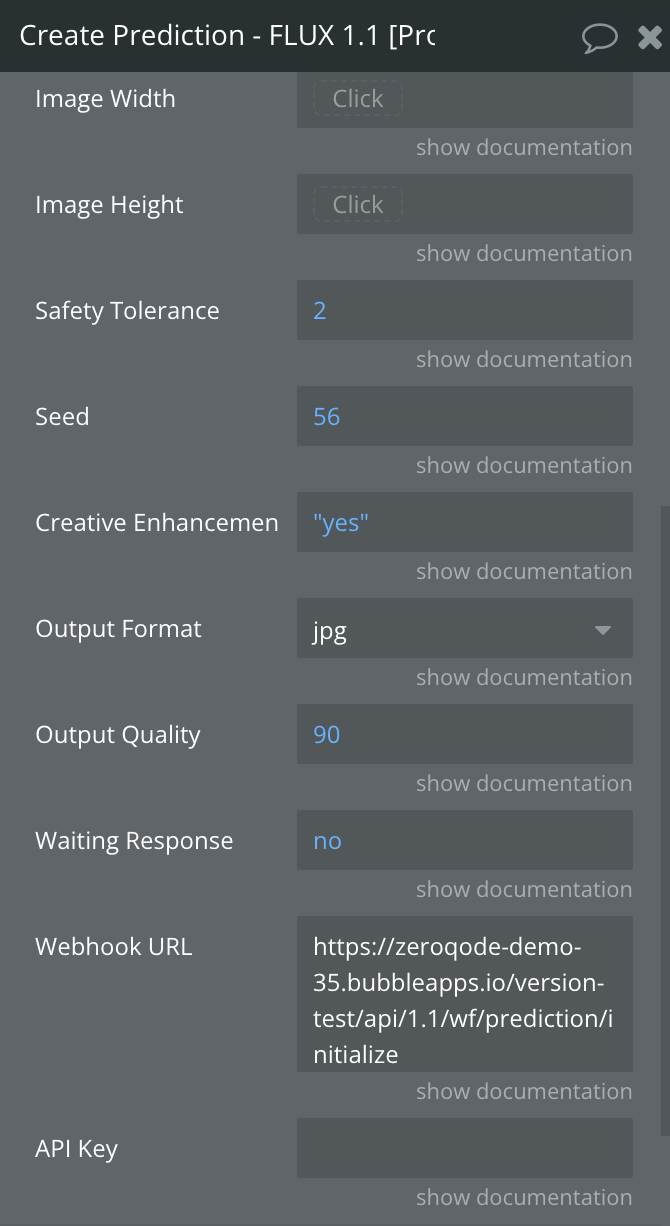

Fields:
Name | Description | Type |
Prompt | A detailed textual description to guide image generation. It defines the visual content, style, and elements to be included in the final image. | Text |
Image Prompt | (Optional) An optional image URL used to guide the model in aligning composition, style, or design. Accepted formats: JPEG, PNG, GIF, and WEBP. | Text (URL) |
Aspect Ratio | Specifies the width-to-height ratio of the image. | Dropdown ( custom,
1:1, 16:9, 3:2, 2:3, 4:5, 5:4, 9:16, 3:4, 4:3 ) |
Image Width | (Optional) Sets the width (in pixels) of the generated image when using custom aspect ratios. Must be a multiple of 32, between 256 and 1440. Ignored if "Aspect Ratio" is not custom. | Number |
Image Height | (Optional) Sets the height (in pixels) of the generated image when using custom aspect ratios. Must be a multiple of 32, between 256 and 1440. Ignored if "Aspect Ratio" is not custom. | Number |
Safety Tolerance | Define the safety tolerance level for the content in the generated image. Values range from 1 (most strict) to 6 (least strict). Default is 2. | Number |
Seed | (Optional) A random numeric value that ensures reproducibility of the generated image. Using the same seed with identical "Prompt" and "Image Prompt" inputs will generate the same image. | Number |
Creative Enhancement | Automatically modify the prompt for more creative generation. | Yes/No |
Output Format | Sets the format of the generated image. Defaults to "webp". | Dropdown ( webp, jpg, png ) |
Output Quality | (Optional) Sets the quality of the generated image output on a scale from 0 (lowest quality) to 100 (highest quality). This setting does not apply to .png outputs, as they are saved without compression. | Number |
Webhook URL | (Optional) A URL to receive the prediction result asynchronously. The system will send the results to this URL when ready. | Text (URL) |
Waiting for Response | Specifies whether the action should wait for the prediction to complete and return the processed image immediately. | Yes/No |
API Key | (Optional) The API key from your Replicate AI account, used to authenticate requests. Set directly in this field if required for flexibility, but leave it empty here and configure it securely in the plugin settings for safe storage. | Text |
Return values:
Name | Description | Type |
Prediction ID | The unique identifier for the prediction, used to retrieve its status or output. | Text |
Result Image | The generated image, returned when the prediction is successful and completed (only if Waiting for Response is set to “Yes”). | Text List |
Status | The current status of the prediction. | Text |
Error | Any error message encountered during the process. | Text |
Get Prediction
This action retrieves the status and output of a previously created prediction using the provided prediction ID. It returns information about the prediction status, output, and any potential errors.
💡
The API key field is optional. It should only be specified if dynamic key switching is required within the application. The key should be set only in the plugin settings in all other cases.
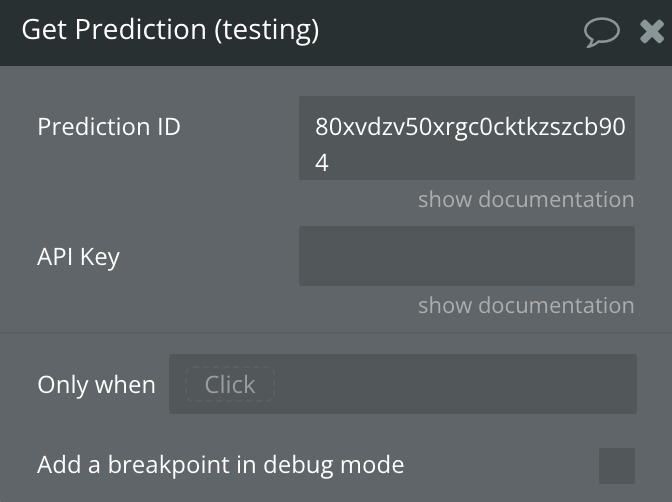
Fields:
Name | Description | Type |
Prediction ID | The unique ID of the prediction to retrieve. | Text |
API Key | (Optional) The API key from your Replicate AI account, used to authenticate requests. Set directly in this field if required for flexibility, but leave it empty here and configure it securely in the plugin settings for safe storage. | Text |
Return values:
Name | Description | Type |
Prediction Output | The result of the prediction, which can be a list of files or a single file depending on the prediction. | Text List |
Prediction Removed | A flag indicating whether the prediction data has been removed or not. | Yes/No |
Prediction Status | The status of the prediction (e.g., "succeeded", "failed", etc.). | Text |
Error | Any error message returned by the prediction API. | Text |
Cancel Prediction
This action cancels an ongoing prediction based on the provided prediction ID. It sends a cancel request to the API and returns the status of the cancellation.
💡
Cancellation is only possible if the prediction status is not
"succeeded". If the prediction has already succeeded, cancellation cannot be performed.💡
The API key field is optional. It should only be specified if dynamic key switching is required within the application. The key should be set only in the plugin settings in all other cases.
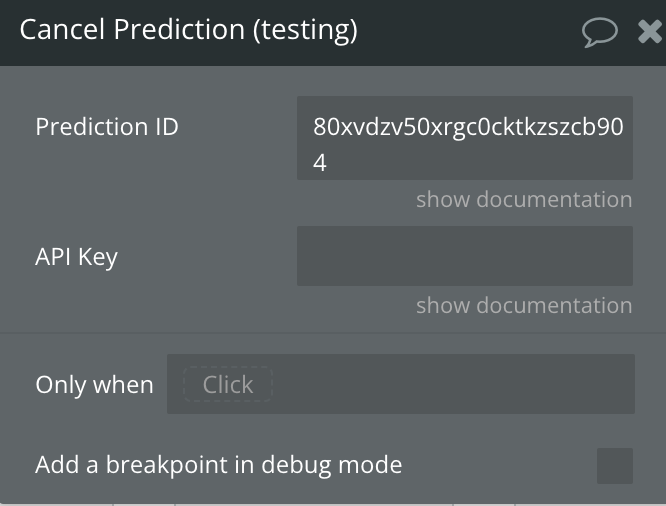
Fields:
Name | Description | Type |
Prediction ID | The unique ID of the prediction to cancel. | Text |
API Key | (Optional) The API key from your Replicate AI account, used to authenticate requests. Set directly in this field if required for flexibility, but leave it empty here and configure it securely in the plugin settings for safe storage. | Text |
Return values:
Name | Description | Type |
Prediction Status | The status of the prediction after attempting to cancel (e.g., "canceled"). | Text |
Error | Any error message returned by the API or a custom error message indicating why the cancellation failed (e.g., if the prediction status prevents cancellation). | Text |
List Predictions
This action retrieves a list of all predictions made with the provided API key. It returns the predictions' status, IDs, and creation dates.
💡
The API key field is optional. It should only be specified if dynamic key switching is required within the application. The key should be set only in the plugin settings in all other cases.
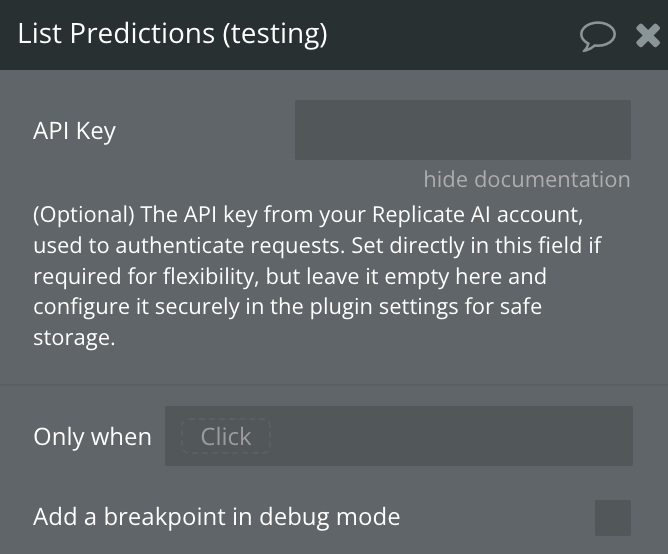
Fields:
Name | Description | Type |
API Key | (Optional) The API key from your Replicate AI account, used to authenticate requests. Set directly in this field if required for flexibility, but leave it empty here and configure it securely in the plugin settings for safe storage. | Text |
Return values:
Name | Description | Type |
Result IDS | A list of prediction IDs for the retrieved predictions. | Text List |
Result Created Dates | A list of the statuses (e.g., "succeeded", "failed") of the retrieved predictions. | Text List |
Result Statuses | A list of the creation dates as text for each of the predictions retrieved. | Text List |
Error | Any error message encountered during the process. | Text |
How To Set Up The Webhooks
💡
Webhook URL is used to receive updates about the status of a prediction, such as completion or failure, without the need for continuous polling. When a webhook URL is provided, the service will send an HTTP POST request to the specified URL containing the prediction status and results.
- In your bubble app → Backend Workflows create a “New API workflow”
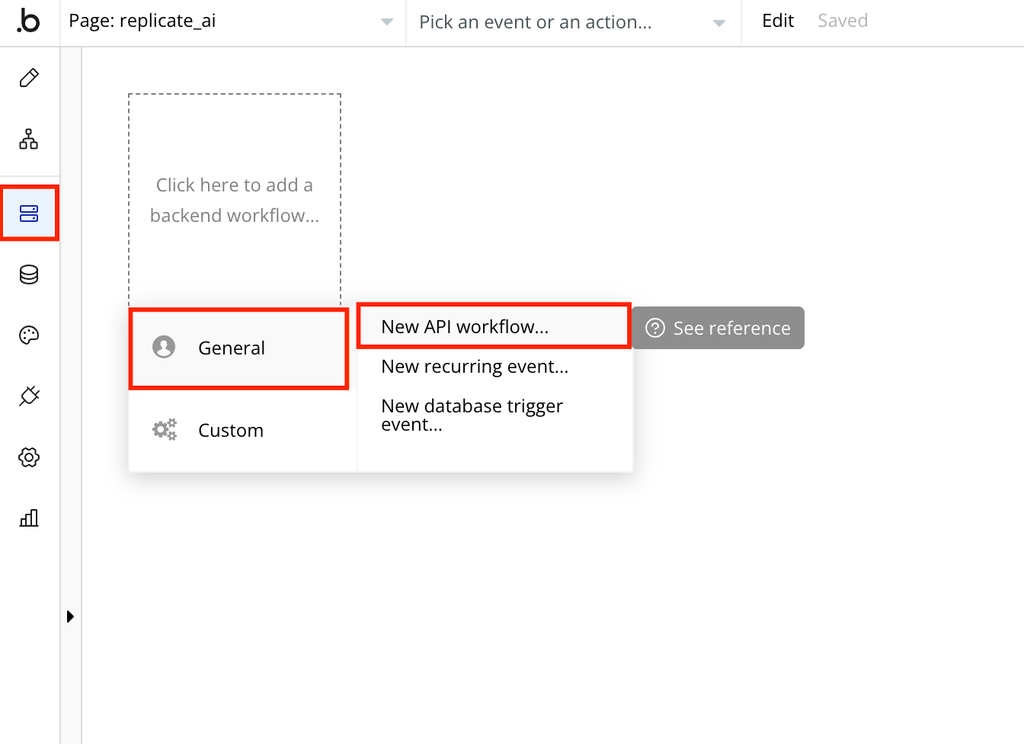
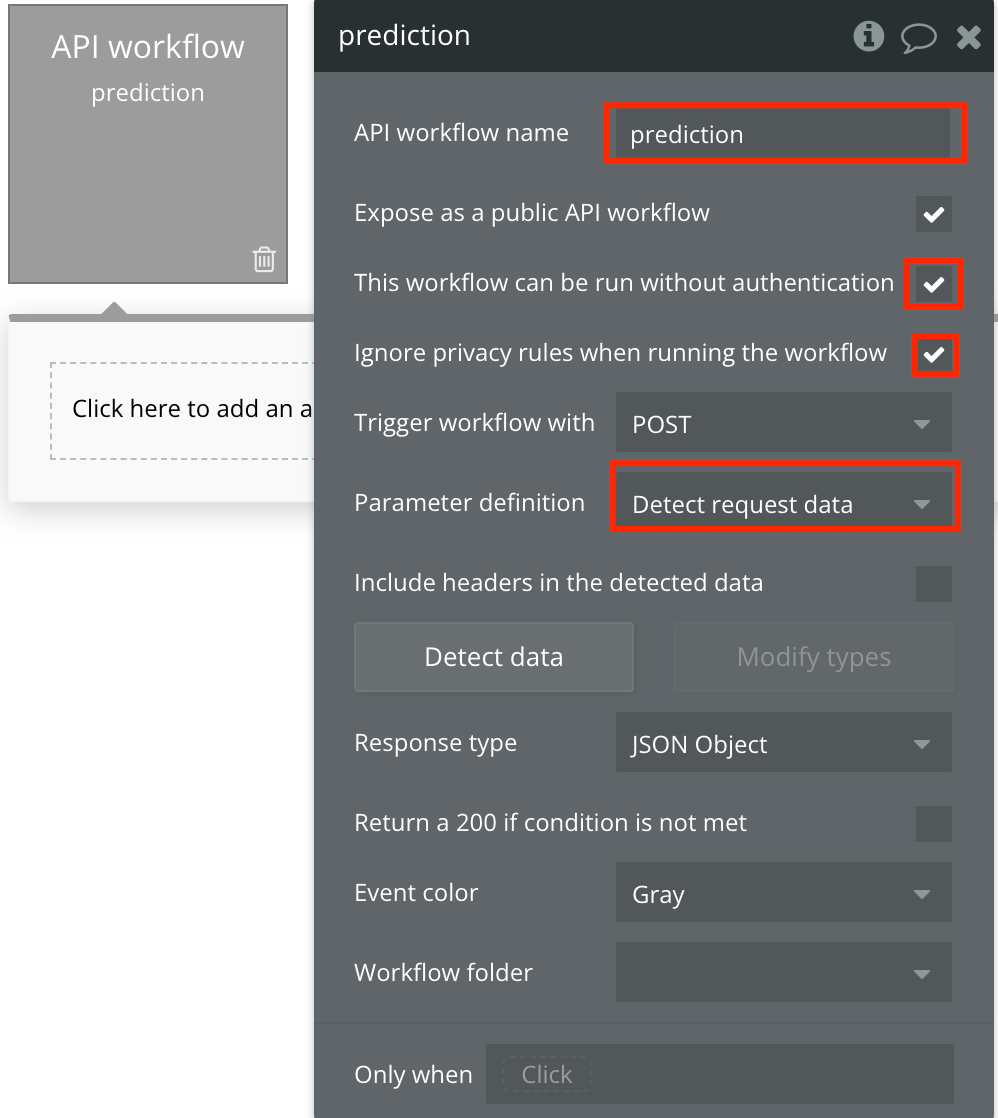
- Give it a name and set it up like in the image
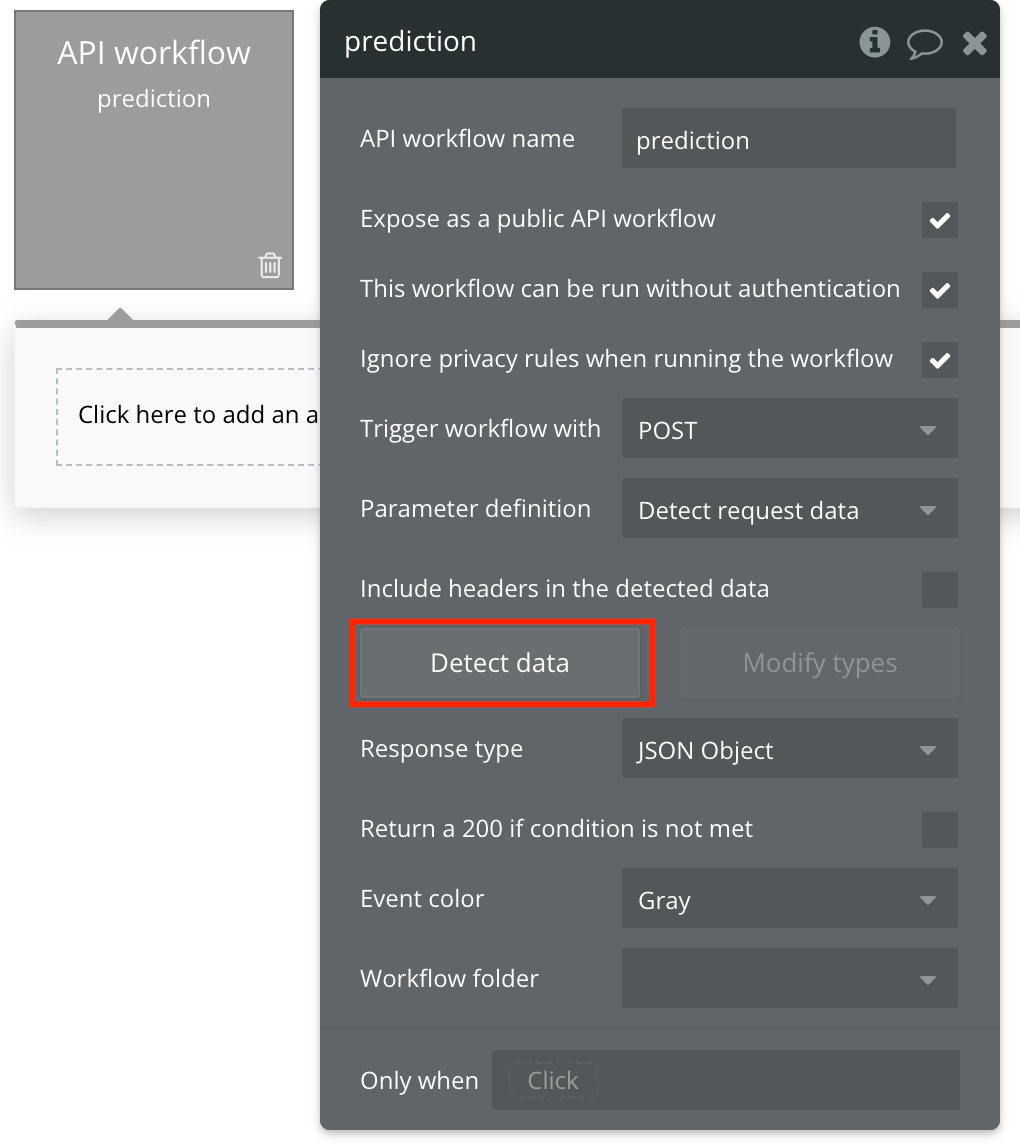
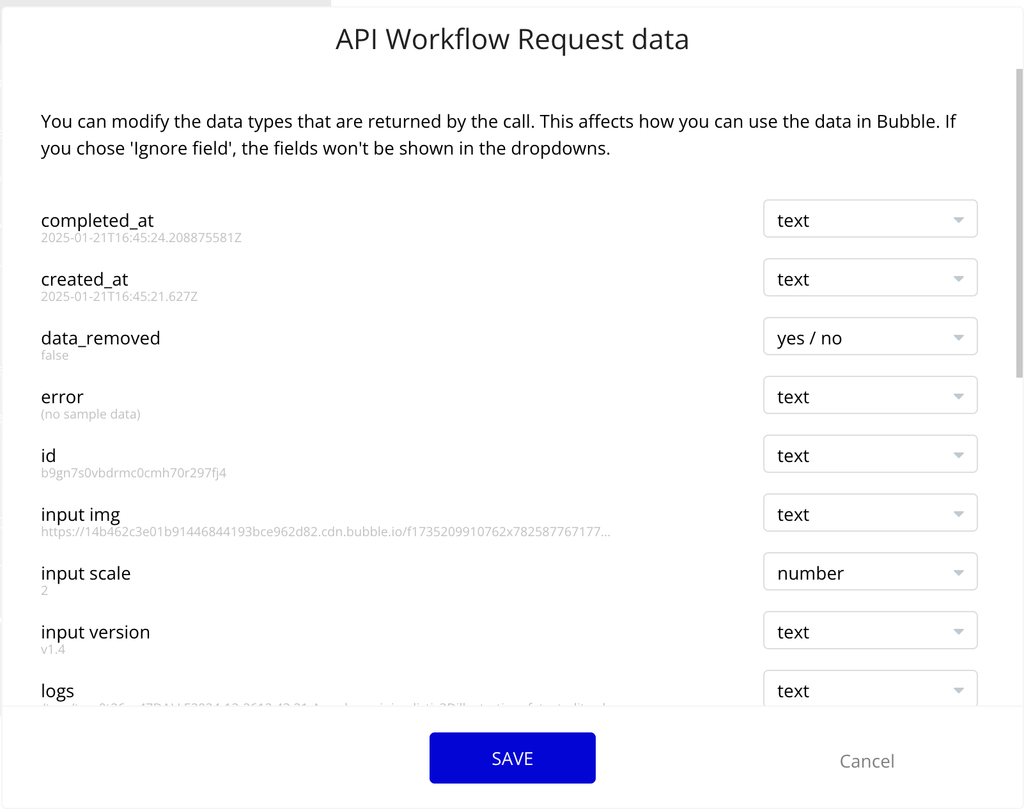
- Click on “Detect data” button and copy the link from the screen.
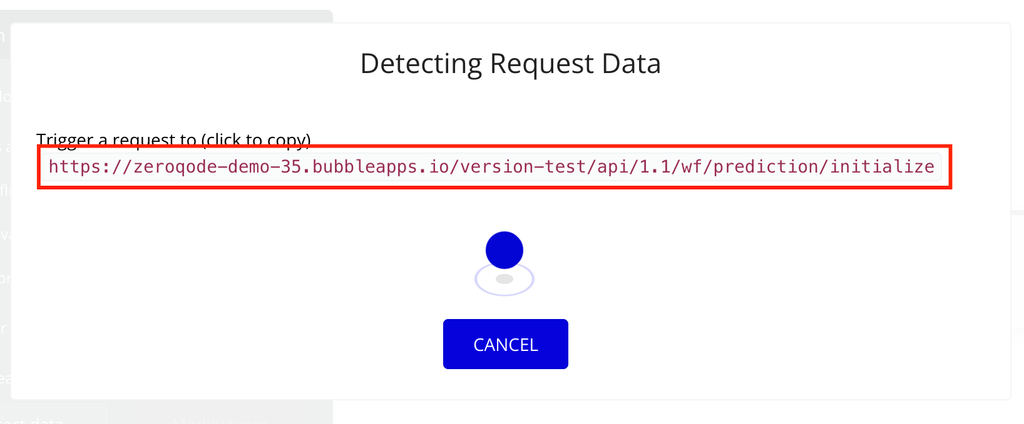
- Meanwhile in a new tab while this tab is still open and detecting, create any prediction with the plugin that has this copied URL set up as the webhook URL.
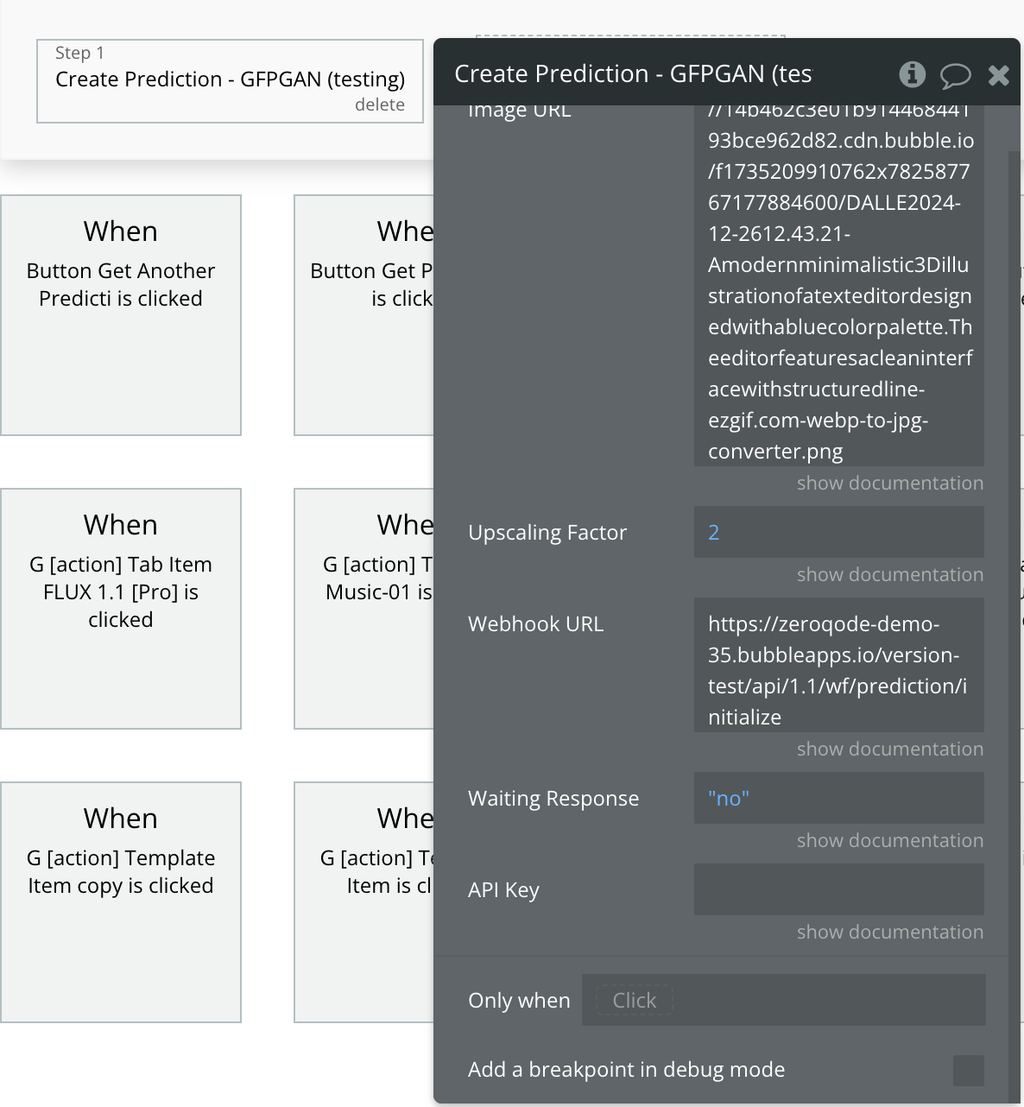
- When the prediction is created, the data will be detected in backend workflows. Now every prediction that has this URL when created will be triggered on updates in backend workflow.

Changelogs
Update 06.03.26 - Version 2.3.0
- Bubble Plugin Page Update (Description).
Update 09.09.25 - Version 2.2.0
- Bubble Plugin Page Update (Forum).
Update 31.07.25 - Version 2.1.0
- Bubble Plugin Page Update (Logo).
Update 13.05.25 - Version 2.0.0
- Minor update (Marketing update).
Update 09.05.25 - Version 1.1.0
- Minor update (Marketing update).
Update 26.02.25 - Version 1.0.0
- Initial plugin release.