
Plugin Introduction
With 175 billion parameters GPT-3 is by far the most powerful text based AI created. GPT-3 (Generative Pre-trained Transformer 3) is a language model that was created by OpenAI, an artificial intelligence research laboratory in San Francisco. The 175-billion parameter deep learning model is capable of producing human-like text and was trained on large text datasets with hundreds of billions of words.
GPT-3 is the third generation of the GPT language models created by OpenAI. The main difference that sets GPT-3 apart from previous models is its size. GPT-3 contains 175 billion parameters, making it 17 times as large as GPT-2, and about 10 times as Microsoft’s Turing NLG modelOn our demo page we show a few use cases out of multitude possibilities:
- Composing a text provided the first sentence
- Chatting with AI
- Text summarization for a 2nd grader
- Translations from one language to another
We couldn't find information on which languages GPT-3 speaks so we decided to ask her! :) Here is the list of languages she said she speaks:
- English
- German
- French
- Italian
- Spanish
- Portuguese
- Simplified Chinese
- Japanese
- Thai
To see many more examples of how you can use this plugin please visit the examples here: https://beta.openai.com/examples as you can see from the link above here are some other possible use cases:
- Classify items into categories via example
- Convert movie titles into emoji
- Turn a product description into ad copy
- A message-style chatbot that can aswer questions about using JavaScript
- Extract contact information from a block of text.
- Convert first-person POV to the third-person
- Turn a few words into a restaurant review.and much more!
Some people even managed to use GPT-3 to write code for them - https://analyticsindiamag.com/open-ai-gpt-3-code-generator-app-building/
At the moment this plugin uses Zeroqode's API keys to Open AI however at any time later this might change and you'll be either requested to obtain your own GPT-3 keys from OpenAI or sign up at Zeroqode to get plugin keys to be billed by the API usage.
Engines
OpenAI’s API provides access to several different engines - Ada, Babbage, Curie and Davinci.
While Davinci is generally the most capable engine, the other engines can perform certain tasks extremely well and in some cases significantly faster. The other engines have cost advantages. For example, Curie can perform many of the same tasks as Davinci, but faster and for 1/10th the cost. We encourage developers to experiment with using the other models and try to find the one that’s the most efficient for your application.
Engine comparisons
Davinci
Davinci is the most capable engine and can perform any task the other models can perform and often with less instruction. For applications requiring a lot of understanding of the content, like summarization for a specific audience and content creative generation, Davinci is going to produce the best results. The trade-off with Davinci is that it costs more to use per API call and other engines are faster.
Another area where Davinci shines is in understanding the intent of text. Davinci is quite good at solving many kinds of logic problems and explaining the motives of characters. Davinci has been able to solve some of the most challenging AI problems involving cause and effect.
Good at: Complex intent, cause and effect, summarization for audience
Curie
Curie is extremely powerful, yet very fast. While Davinci is stronger when it comes to analyzing complicated text, Curie is quite capable for many nuanced tasks like sentiment classification and summarization. Curie is also quite good at answering questions and performing Q&A and as a general service chatbot.
Good at: Language translation, complex classification, text sentiment, summarization
Babbage
Babbage can perform straightforward tasks like simple classification. It’s also quite capable when it comes to Semantic Search ranking how well documents match up with search queries.
Good at: Moderate classification, semantic search classification
Ada
Ada is usually the fastest model and can perform tasks like parsing text, address correction and certain kinds of classification tasks that don’t require too much nuance. Ada’s performance can often be improved by providing more context.
Good at: Parsing text, simple classification, address correction, keywords
Note: Any task performed by a faster model like Ada can be performed by a more powerful model like Curie or Davinci.
Finding the right engine
Experimenting with Davinci is a great way to find out what the API is capable of doing. After you have an idea of what you want to accomplish you can either stay with Davinci if you’re not concerned about cost and speed or move onto Curie or another engine and try to optimize around its capabilities.
You can use this tool that lets you run different engines side-by-side to compare outputs, settings and response times and then download the data into a .xls spreadsheet: https://gpttools.com/comparisontool.
Languages
The AI can understand and will answer in many languages, like English, French, Japanese, Korean, Mandarin, Arabic, and many others.
Plugin Data/Action Calls
Action Calls
- Create Completion - Given a prompt, the model will return one or more predicted completions, and can also return the probabilities of alternative tokens at each position.
Params:
initial_text - The prompt(s) to generate completions for, encoded as a string, a list of strings, or a list of token lists.Note that <|endoftext|> is the document separator that the model sees during training, so if a prompt is not specified the model will generate as if from the beginning of a new document.
max_tokens - The maximum number of tokens to generate. Requests can use up to 2048 tokens shared between prompt and completion. (One token is roughly 4 characters for normal English text).
temperature - What sampling temperature to use. Higher values means the model will take more risks. Try 0.9 for more creative applications, and 0 (argmax sampling) for ones with a well-defined answer. We generally recommend altering this or top_p but not both.
top_p - An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered.We generally recommend altering this or temperature but not both.
stop - Up to 4 sequences where the API will stop generating further tokens. The returned text will not contain the stop sequence.
best_of - Generates
best_of completions server-side and returns the "best" (the one with the lowest log probability per token). Results cannot be streamed.When used with
n, best_of controls the number of candidate completions and n specifies how many to return – best_of must be greater than n.
Note: Because this parameter generates many completions, it can quickly consume your token quota. Use carefully and ensure that you have reasonable settings for max_tokens and stop.
logprobs - Include the log probabilities on the logprobs most likely tokens, as well the chosen tokens. For example, if logprobs is 10, the API will return a list of the 10 most likely tokens. the API will always return the logprob of the sampled token, so there may be up to logprobs+1 elements in the response.
n - How many completions to generate for each prompt.Note: Because this parameter generates many completions, it can quickly consume your token quota. Use carefully and ensure that you have reasonable settings for
max_tokens and stop.Generate- The API call to generate a response to a given context. Params are the same as "Create Completion"'s params.
- List Engines - Return the list of existing engines.
- Search - The Search endpoint (/search) allows you to do a semantic search over a set of documents. This means that you can provide a query, such as a natural language question or a statement, and the provided documents will be scored and ranked based on how semantically related they are to the input query. The "documents" can be words, sentences, paragraphs, or even longer documents. For example, if you provide documents ["White House", "hospital", "school"] and query "the president", you’ll get a different similarity score for each document. The higher the similarity score, the more semantically similar the document is to the query (in this example, "White House" will be most similar to "the president"). Params: engine_id - The ID of the engine to use for this request.
documents - Up to 200 documents to search over, provided as a list of strings.The maximum document length (in tokens) is 2034 minus the number of tokens in the query.
query - Query to search against the documents.
- Summarize text like for 2nd grader - This call allows you to create a resume from a large source text in a short understanding for a 2nd-grade child.
Params:
engine_id - The ID of the engine to use for this request.
Text - The original text to be summarized
temperature - What sampling temperature to use. Higher values mean the model will take more risks. Try 0.9 for more creative applications, and 0 for ones with a well-defined answer.
max_tokens - The maximum number of tokens to generate. Requests can use up to 2048 tokens shared between prompt and completion. (One token is roughly 4 characters for normal English text).
top_p - An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered.We generally recommend altering this or temperature but not both.
- Translator - this call helps you to translate from one language into another selected language.
Params:
engine_id - The ID of the engine to use for this request.
text - Source text to be translated
Initial_language - source language
Desired_language - language to be translated
temperature - What sampling temperature to use. Higher values mean the model will take more risks. Try 0.9 for more creative applications, and 0 for ones with a well-defined answer.
max_tokens - The maximum number of tokens to generate. Requests can use up to 2048 tokens shared between prompt and completion. (One token is roughly 4 characters for normal English text).
top_p - An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered.
We generally recommend altering this or temperature but not both.
Plugin Action
Generate text
An action that includes two calls to "Create Completion" and "Search" to create the text closest to the initial text in meaning.
Params:
- prompt - The prompt(s) to generate completions for, encoded as a string, a list of strings, or a list of token lists.Note that <|endoftext|> is the document separator that the model sees during training, so if a prompt is not specified the model will generate as if from the beginning of a new document.
- Hash - Unique number to make a unique request.
- Temperature - What sampling temperature to use. Higher values means the model will take more risks. Try 0.9 for more creative applications, and 0 (argmax sampling) for ones with a well-defined answer.We generally recommend altering this or top_p but not both.
- Max tokens - The maximum number of tokens to generate. Requests can use up to 2048 tokens shared between prompt and completion. (One token is roughly 4 characters for normal English text).
- Top_p - An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered.We generally recommend altering this or temperature but not both.
- stop - Up to 4 sequences where the API will stop generating further tokens. The returned text will not contain the stop sequence.
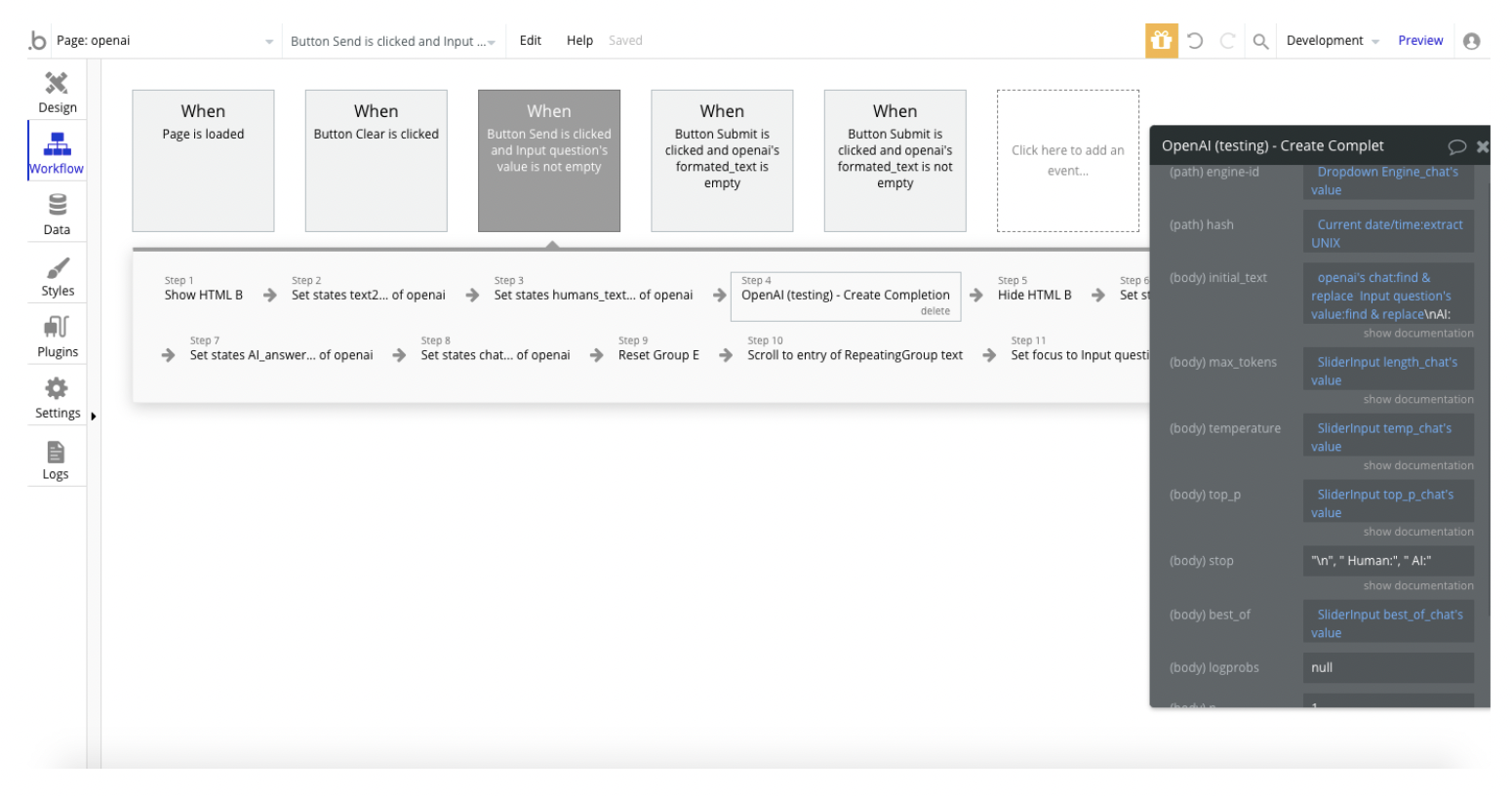
Workflow example
To demonstrate how to use plugin actions, we'll show you an example from our demo page.
The whole workflow is state-based. To get an accurate result, you need to use the states correctly.